# 教程(Tutorial)
这一部分为Scatlas的使用教程,面向即将使用Scatlas建模的直接用户或仅仅是对Scatlas感兴趣的读者,只要有供应链基础知识,任何人可以轻松掌握使用Scatlas建立基础供应链模型的技能。
此时有些读者也许面临着实际的业务问题,迫切地想要通过Scatlas解决这些问题,我建议跳过第一章,直接阅读第二章“如何使用Scatlas”。而对于不这么着急的读者,按照顺序阅读即可。
# 为何使用Scatlas?
使用Scatlas的目的是做供应链优化。本章将介绍Scatlas的使用场景和主要功能。
# Scatlas能做什么?
Scatlas可以提升供应链运作效率,可视化供应链成本,辅助供应链管理层进行多场景决策。具体包括仓网布局、库存策略、产品流优化、滚动需求计划以及供应链细分策略等。
以下将介绍一些实际的业务场景和Scatlas的强大功能。
# Mock Case 1:Polar Bear
# 项目背景
A公司是一家知名的服装公司,主营产品为羽绒服,其销售网络遍布中国。 在全国拥有上千家的直营店和加盟店。近几年,服装企业的竞争日趋激烈,利润逐年下降,库存和成本压力逐步加大。
# 痛点/优化点
企业花在运输、仓储方面的成本太高,想要通过仓网布局的优化减少运输、仓储成本,却不知道如何下手。
# Scatlas方案
使用选址+网络优化算法,使仓库数量从58个减少到25个,运输成本下降3.24%,约100w人民币。
# Mock Case 2:LX Milk
# 项目背景
LX Milk是一家知名的乳制品公司,其销售网络遍布中国。 其主要的业务单元之一AA拥有16家工厂,可生产20种产品,主要发往分布全国的55个客户。而这些产品所需的关键原料——原奶则来自14个奶源供应地。
项目范围内的成本包括工厂生产成品的生产成本,奶源-工厂、工厂间调拨和工厂-各省营销分公司的运输成本,原奶产量多于需求量造成的丢弃成本208元/吨。(多余的原奶会被制作成奶粉,丢弃成本即喷粉费用)。
# 痛点/优化点
LX Milk公司希望通过软件优化月度产销主计划,优化生产和运输成本、提高产能利用率。
# Scatlas方案
通过包括生产端的网络优化(NO)算法,优化产能布局,放开工厂生产产品种类的限制,关闭了一些产线使开工产线的产能利用率提高,降低了生产成本;优化运输线路,降低配送平均距离,降低了运输成本。优化结果:总成本下降了5.8%,大约383W元;生产成本下降了3.8%,大约210W元;运输成本下降了21.2%,大约178W元。
# 如何使用Scatlas
使用Scatlas建模一般符合以下流程:
# Mock Case 1:Polar Bear
# 如何反映历史现状?搭建Baseline基准模型。
# 模型假设
产品:整合为羽绒服一种产品
门店:门店按照城市和门店类型进行整合
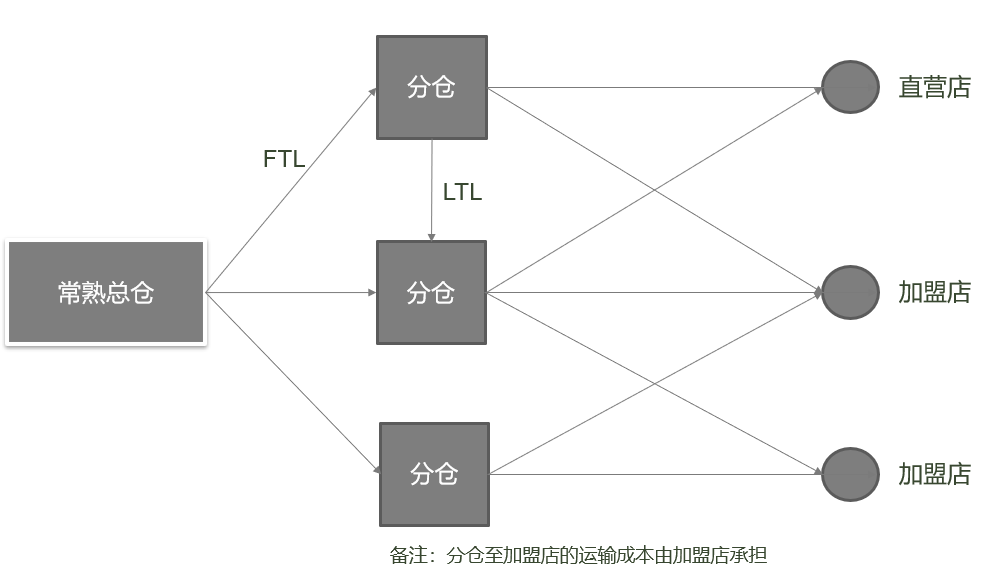
运输模式:从总仓到分仓使用FTL(整车)输运模式,从分仓到门店使用LTL(零担)输运模式
缺失的运输费用:根据原始数据中的运输报价预测
# 原始数据
# 原始数据下载
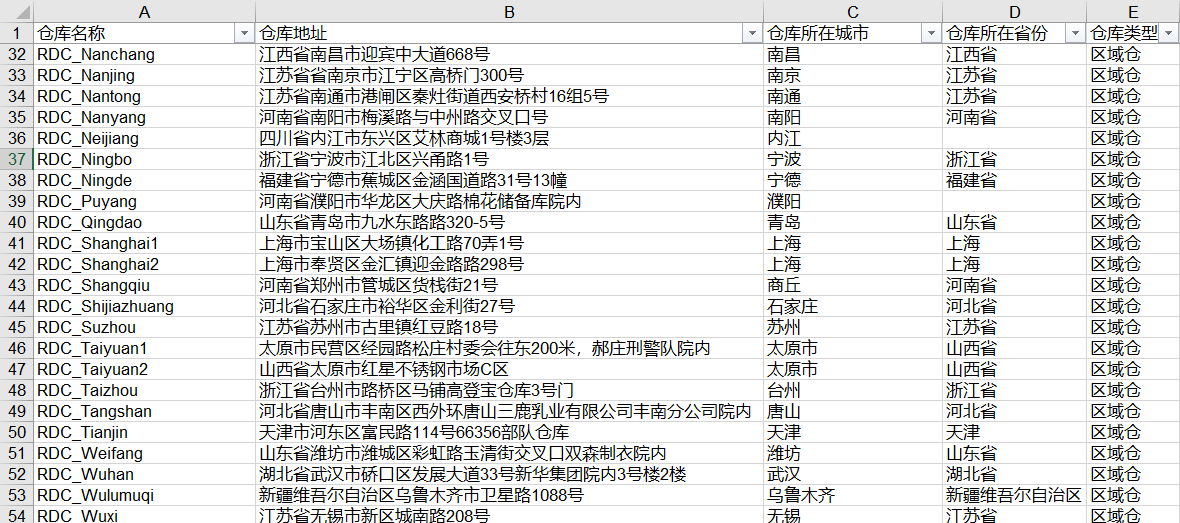
仓库信息
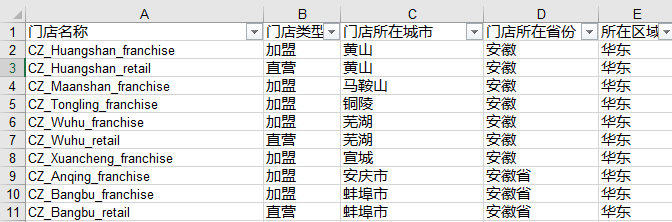
门店信息
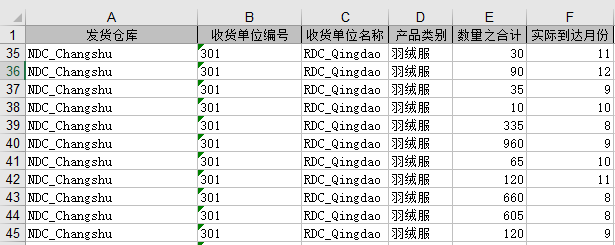
发运记录(总仓-分仓)
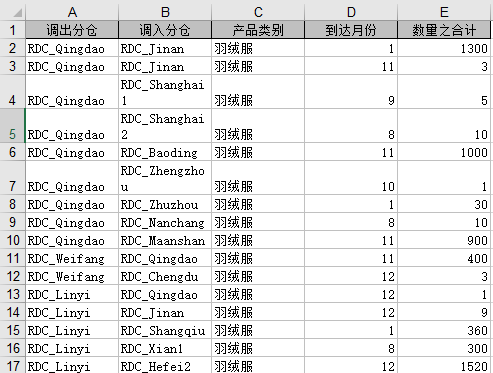
发运记录(分仓-分仓)
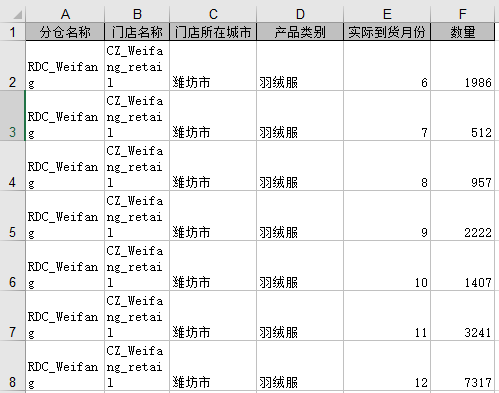
发运记录(分仓-门店)
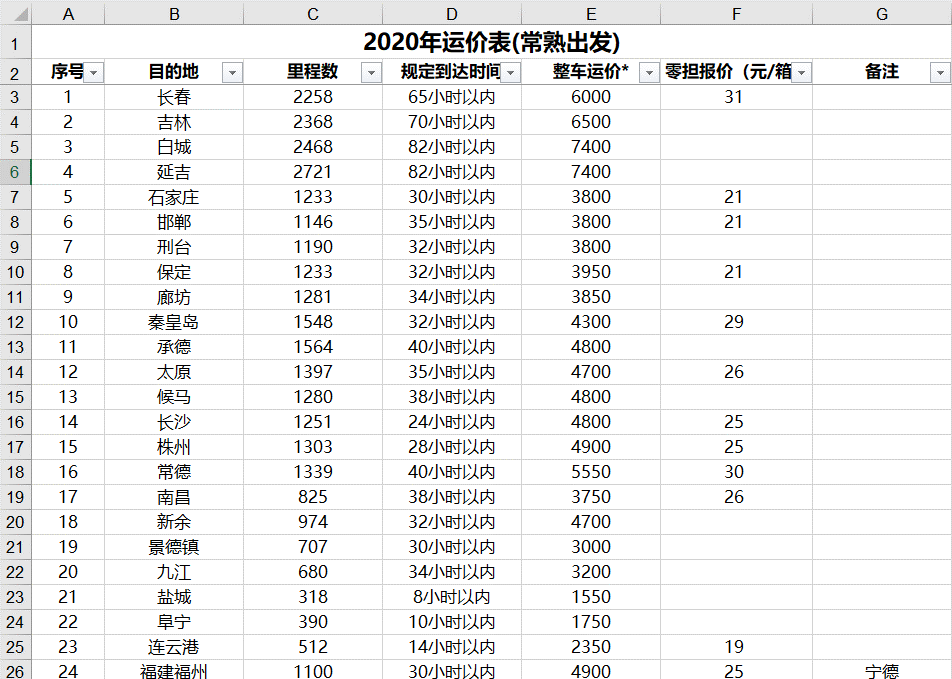
运输报价
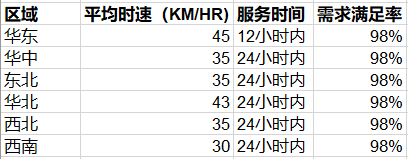
选址-服务要求
# 模型输入
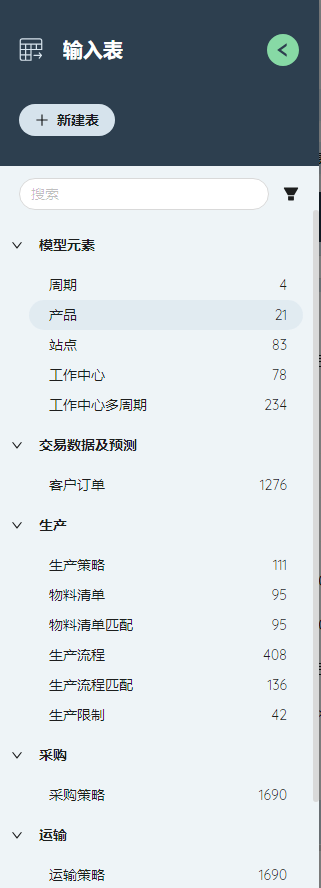
在运行模型之前,数据以表格的形式输入。
不同的算法所需的模型输入各不相同,其中又分为必需输入和可选输入,比如NO的必需输入表为周期、产品、站点、客户订单、生产策略、采购策略、运输策略、库存策略,而GF的必需输入表只需要站点、客户订单。由于Scatlas的数据表表头都是固定的,原始数据需要按固定的格式输入。
接下来将介绍Baseline基准模型所需的输入表,包括使用到的字段的含义、字段的值与原始数据之间的对应关系。
点击左侧功能栏的输入表,选择对应的表格填写。
周期
周期表表示模型的时间范围,从开始到结束的这段时间内可以只有1个周期,即单周期模型,也可以有多个周期,即多周期模型。
周期表-单周期
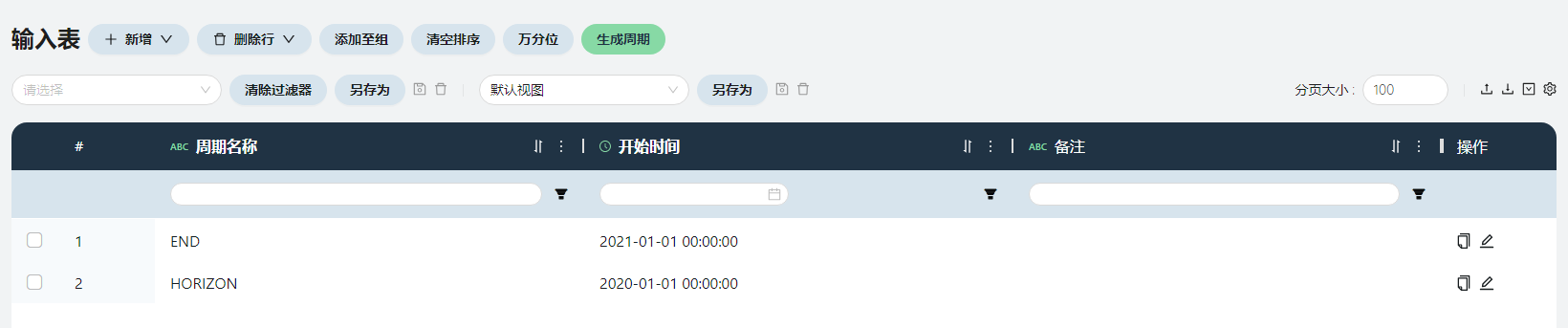
周期名称
时间周期的名称,HORIZON指整个模型的开始时间,END指整个模型的结束时间,必须包含END。
开始时间
HORIZON的开始时间设置为2020-01-01
END的开始时间设置为2021-01-01
产品
产品表记录了产品本身的属性。
产品表

产品名称
产品已经被整合,只有羽绒服一种,故产品名称只用填写一个羽绒服。
站点
站点表包括总仓、分仓、门店的位置、区域信息。
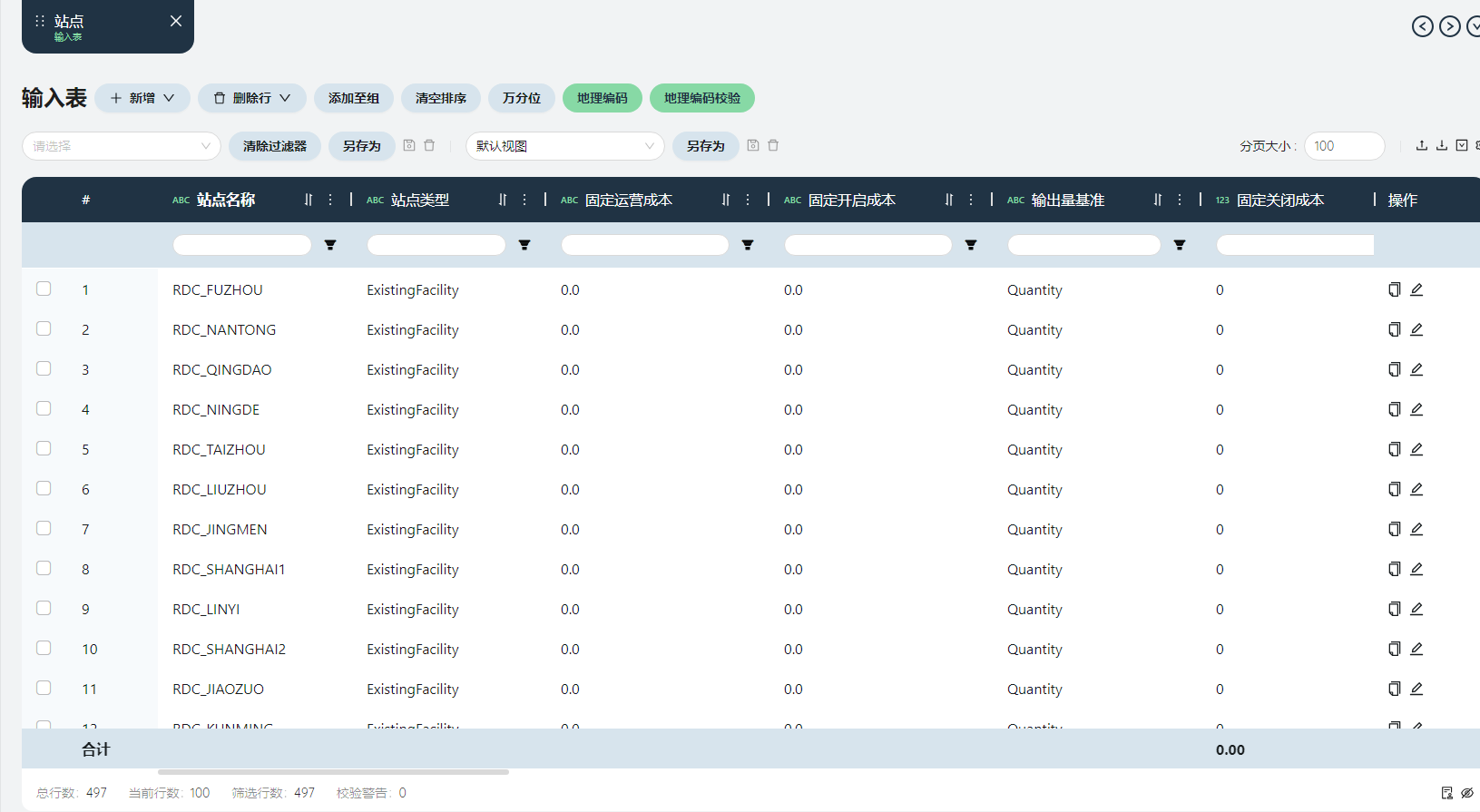
站点表
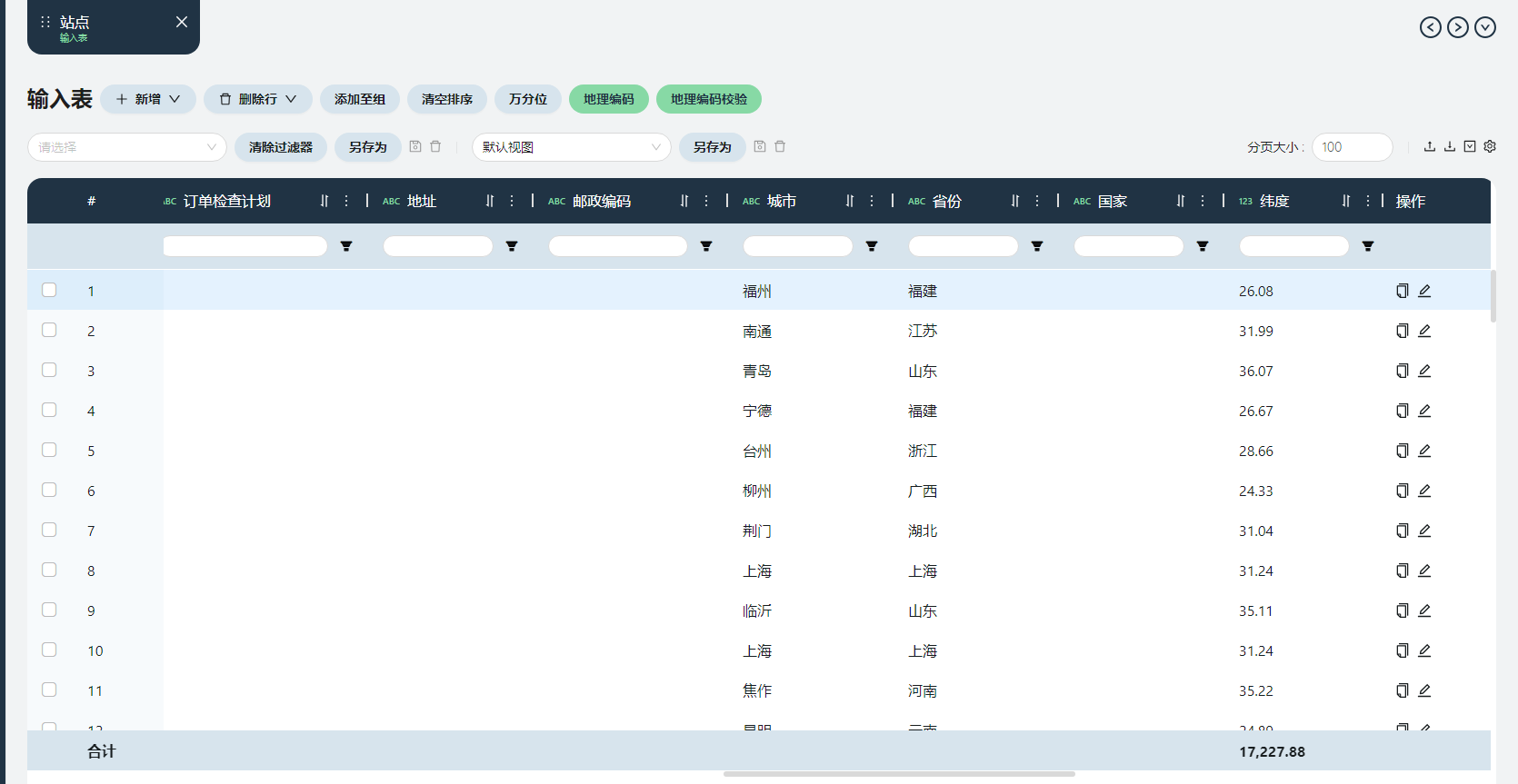
站点名称
即原始数据-仓库信息/门店信息中的仓库名称/门店名称。
仓库信息 门店信息
站点类型
产生需求订单的客户为Customer,工厂/仓库等为ExistingFacility
城市
原始数据-仓库信息/门店信息中的仓库所在城市/门店所在城市
仓库信息 门店信息
省份
原始数据-仓库信息/门店信息中的仓库所在省份/门店所在省份
仓库信息 门店信息
纬度/经度
填写完城市和省份后,点击站点表上方的地理编码按钮,自动查询经纬度
备注
根据原始数据-门店信息中的所在区域列填写。
客户订单
客户订单表记录了每个客户订购每种产品的时间和数量,根据原始数据-发运记录(分仓-门店)根据门店名称、产品类别、实际到货月份聚合数量之和。需要填写客户名称、产品名称、订单日期、数量。
客户订单表
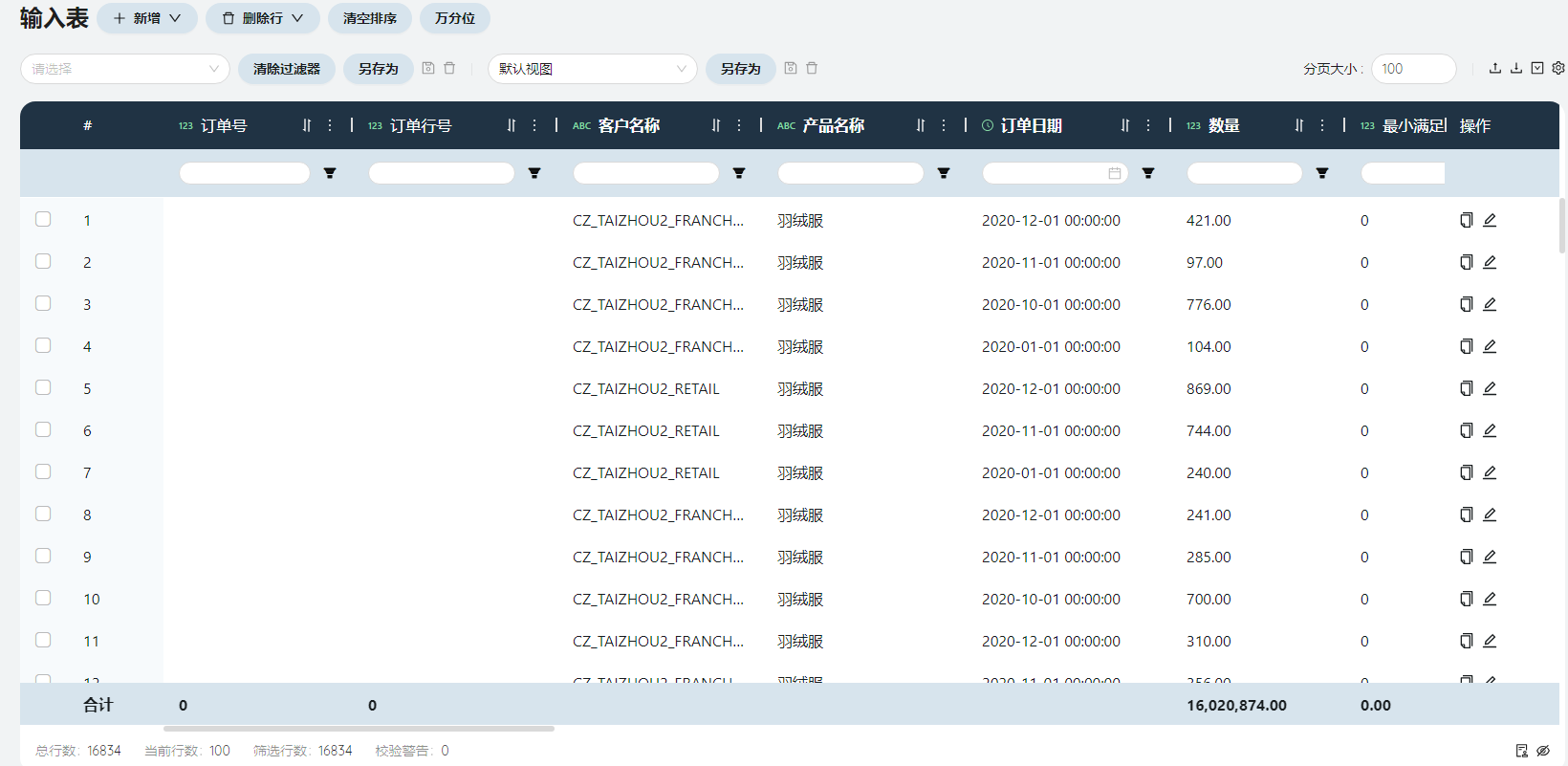
订单日期
根据原始数据-发运记录(分仓-门店)的实际到货月份字段,改为2020年该月1日
数量
每月每个客户采购每种产品的数量。
生产策略
生产策略记录了产品的生产来源、生产成本/批量/时间等信息。将总仓看作产品的生产源,可以生产所有产品。需填写站点名称、产品名称。(注意:策略表中出现的站点、产品需在模型元素中出现)
生产策略表

采购策略
采购策略记录了产品在供应链网络中的流向。包括分仓向总仓采购羽绒服、门店向分仓采购羽绒服。需填写起点名称、站点名称、产品名称。根据原始数据-发运记录(总仓-分仓)、原始数据-发运记录(分仓-门店)填写,一行对应着一个起点、站点、产品的组合,不可重复。
采购策略表
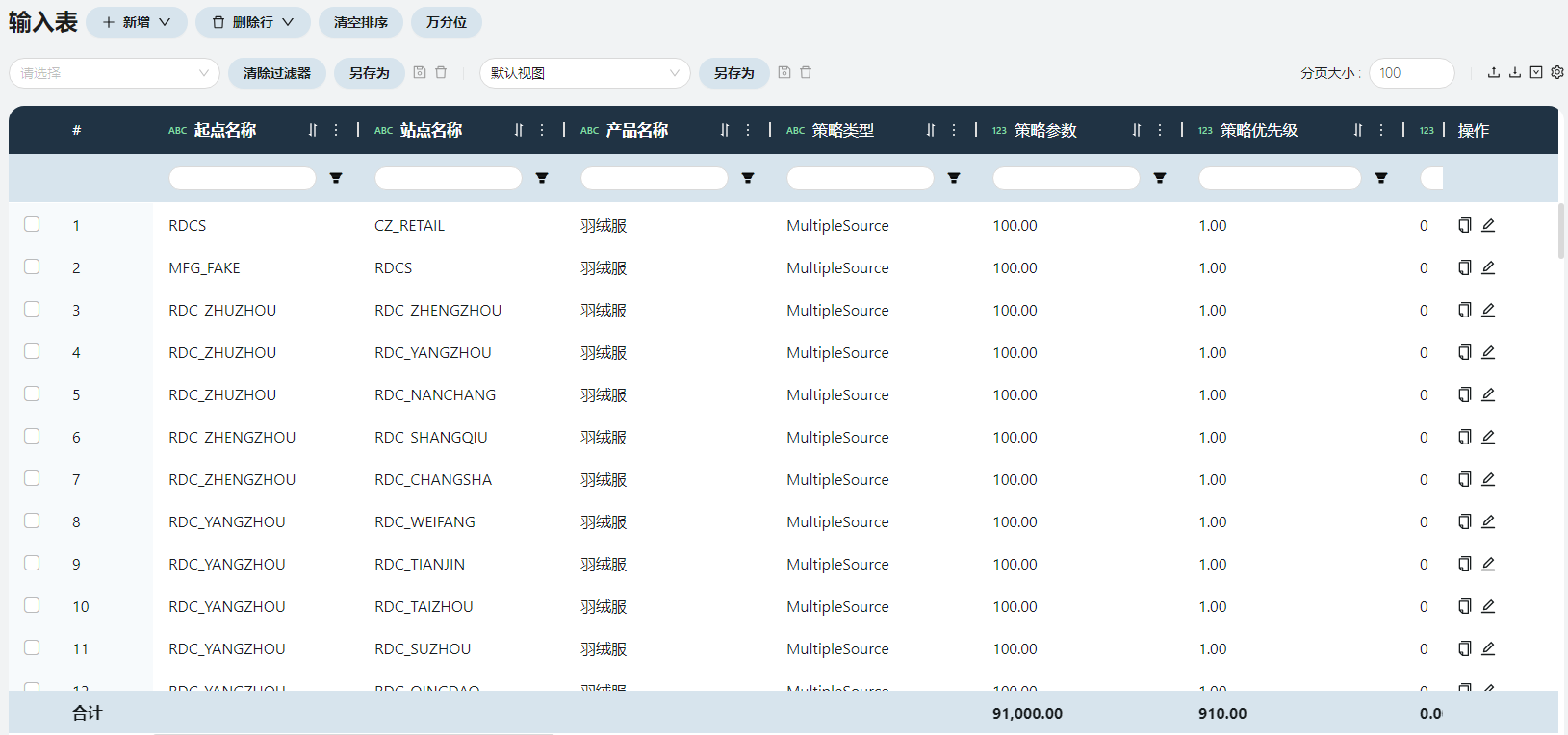
运输策略
运输策略表记录了每一条运输线路的运输模式、距离、运输成本等信息。每行数据与采购策略表对应,在起点/站点/产品名称的基础上增加运输模式名称/功能、距离、变动运输成本、变动成本基准、固定运输成本的信息。运费信息来自运输报价中的整车运价、零担报价,缺失的运价结合里程数预测。
运输策略表

运输模式名称/功能
从总仓发往分仓的线路(起点名称为总仓,站点名称为分仓的数据行)运输模式名称为1,运输模式功能为FTL;从分仓发往门店的线路(起点名称为分仓,站点名称为门店的数据行)运输模式名称为2,运输模式功能为LTL。
距离
点击运输策略表上方的距离计算按钮,根据站点表里的经纬度自动查询每一条数据的导航距离。
变动运输成本、变动成本基准、固定运输成本
变动运输成本的含义随变动成本基准变化,例如变动成本基准为QuantityDistance,变动运输成本为0.13,表示每件每公里的变动运输成本为0.13元,变动成本基准为Quantity,变动运输成本为0.26,表示每件的变动运输成本为0.26元;固定运输成本即每运输一批货物(一批默认为一件),需要付出的固定的额外运输成本(例如起步费)。
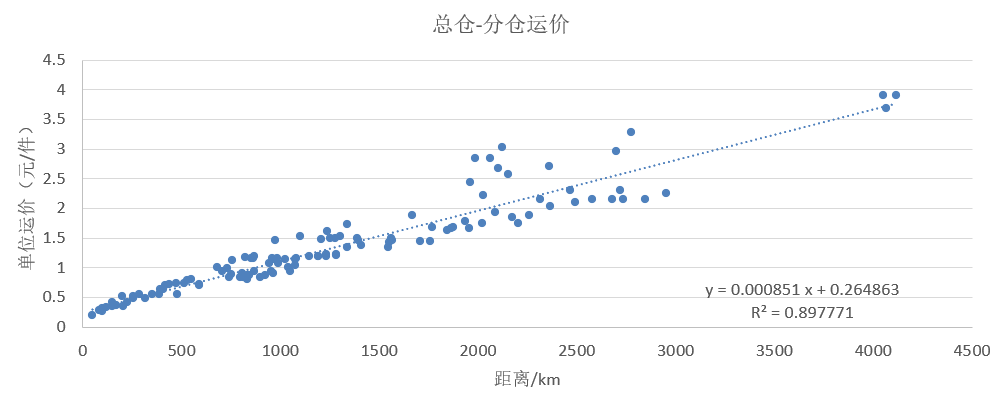
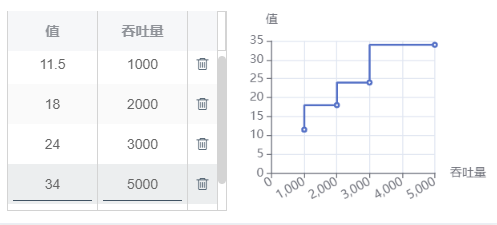
从总仓到分仓:变动运输成本根据原始数据-运输报价填写已有的部分,变动成本基准填写Quantity;运输报价中缺失的部分按照线性回归的方式预测(见下图),变动成本基准为QuantityDistance,每件每公里需要0.000851元的变动运输成本,每件需要0.264863元的固定运输成本。
总仓-分仓运价预测
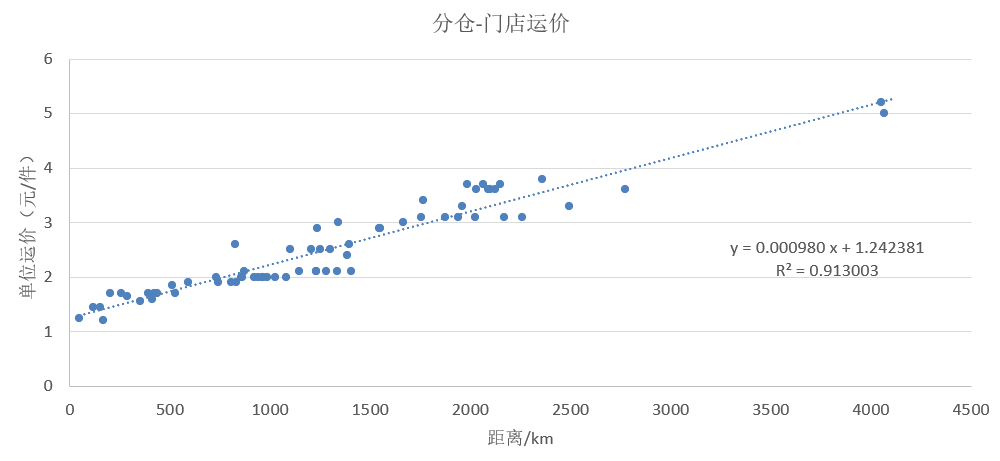
从分仓到门店:按照运输报价中的零担报价以线性回归的方式预测(见下图),变动成本基准为QuantityDistance,每件每公里需要0.000980元的变动运输成本,每件需要1.242381元的固定运输成本。
分仓-门店运价预测
库存策略
羽绒服存放在RDC里。站点名称即原始数据-仓库信息中的RDC名称。
库存策略表
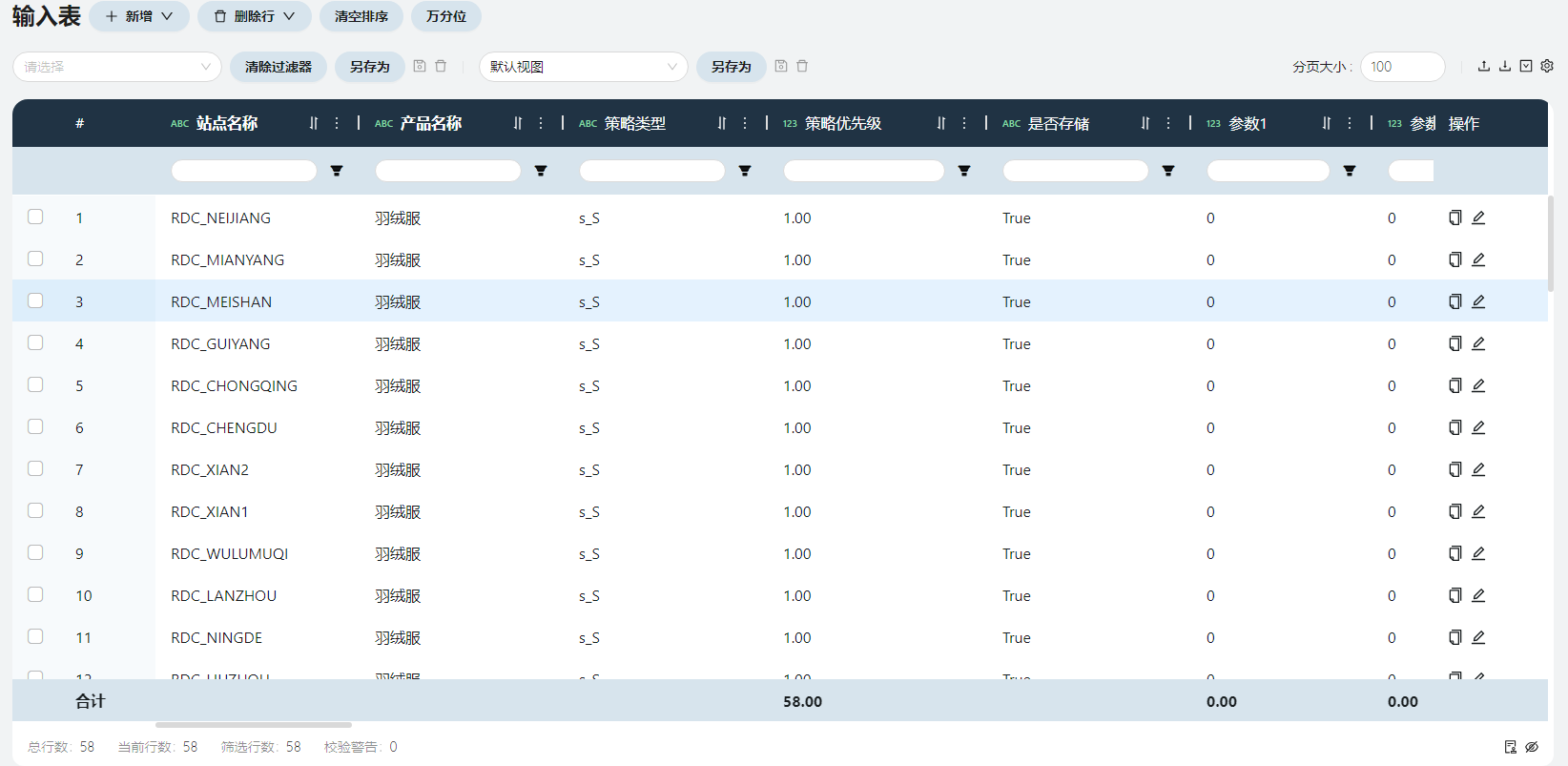
# 模型输出
填写完输入表之后,点击左侧功能栏进入在线任务列表,点击新增任务,勾选Baseline,选择算法“网络优化(NO)”,点击添加,模型开始运行。

运行成功,点击左侧功能栏,选择对应的输出表查看。
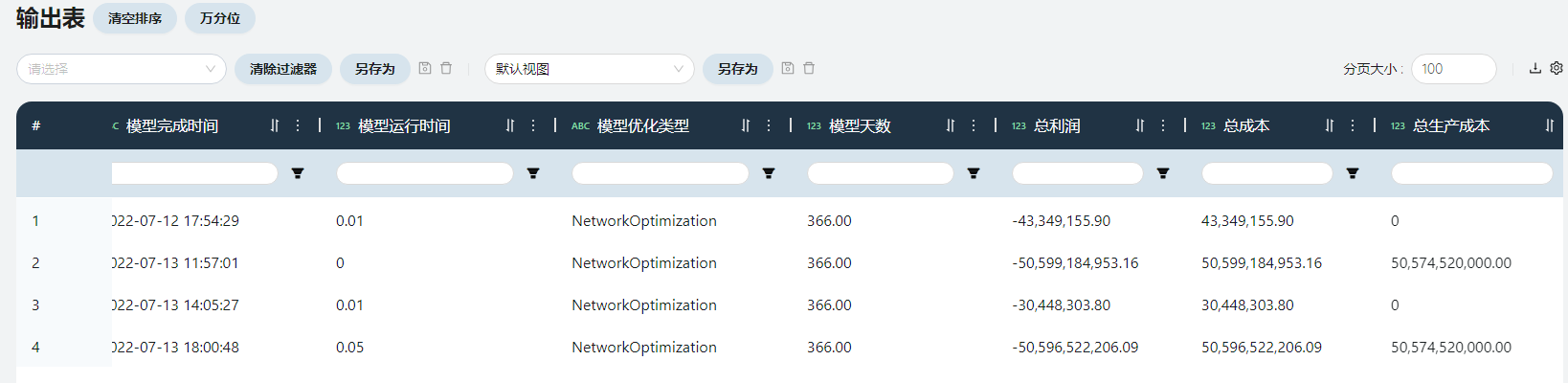
- 网络优化汇总
网络优化汇总展现了总成本的构成细节与总利润、总营收等信息。在此场景内,总成本等于运输成本,大约30,448,304元。
- 网络站点汇总
网络站点汇总展现了每个工厂/仓库等ExistingFacility的优化状态、吞吐量(出库流量)、与之相关的总成本(包括入库运输、出库运输、仓库出入库)。
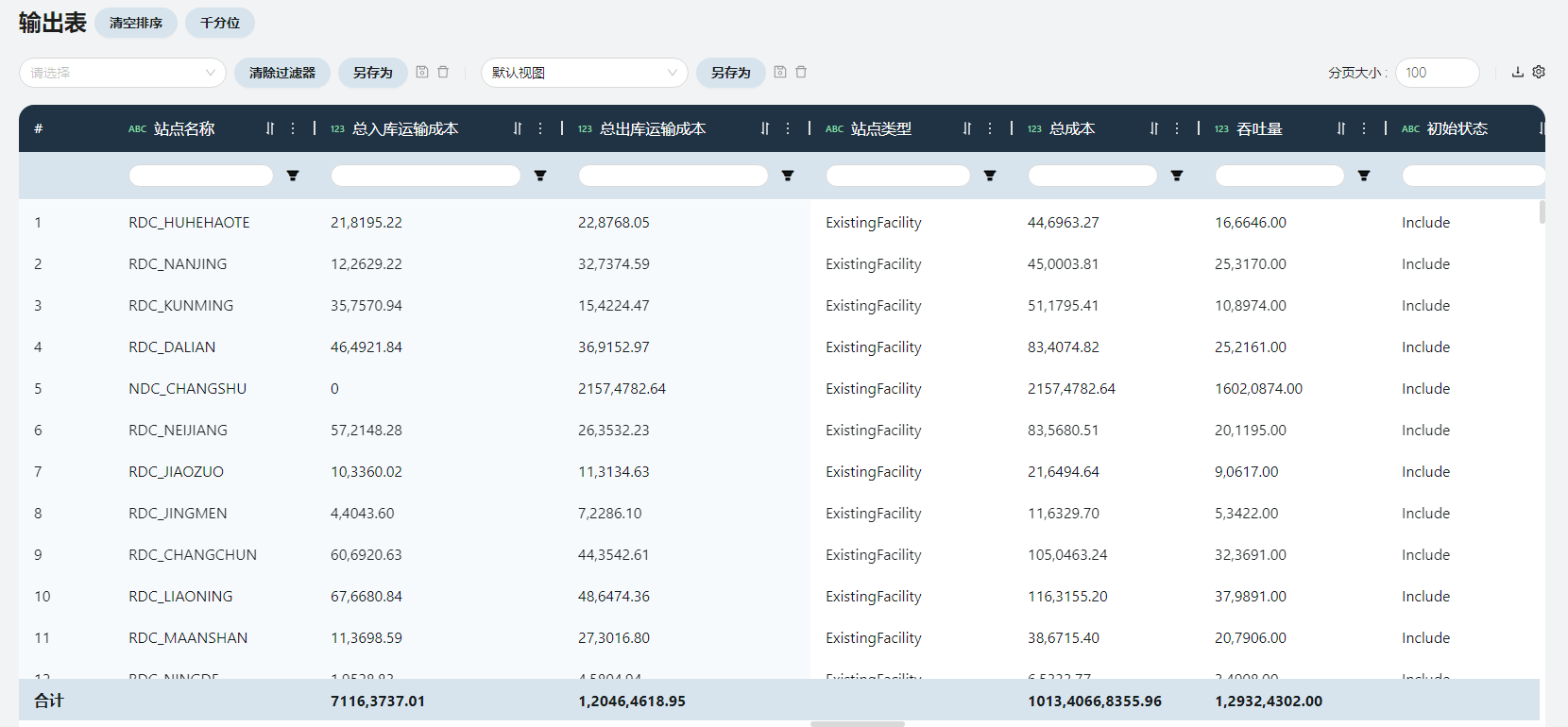
优化状态
若现存设施存在阶梯状的固定运营成本,表示该设施处于第几个阶梯上。
吞吐量/吞吐量基准
表示设施的出库流量以及吞吐量的单位(Quantity/Weight/Volume对应 个/kg/M3)。
总入库运输成本/总出库运输成本
表示进入该设施的货物的运输成本和从该设施出发的货物的运输成本。
- 运输流量
展现了每条线路上通过每种运输方式运输每种产品的流量、服务距离、服务时效、运输成本、在途库存等信息。
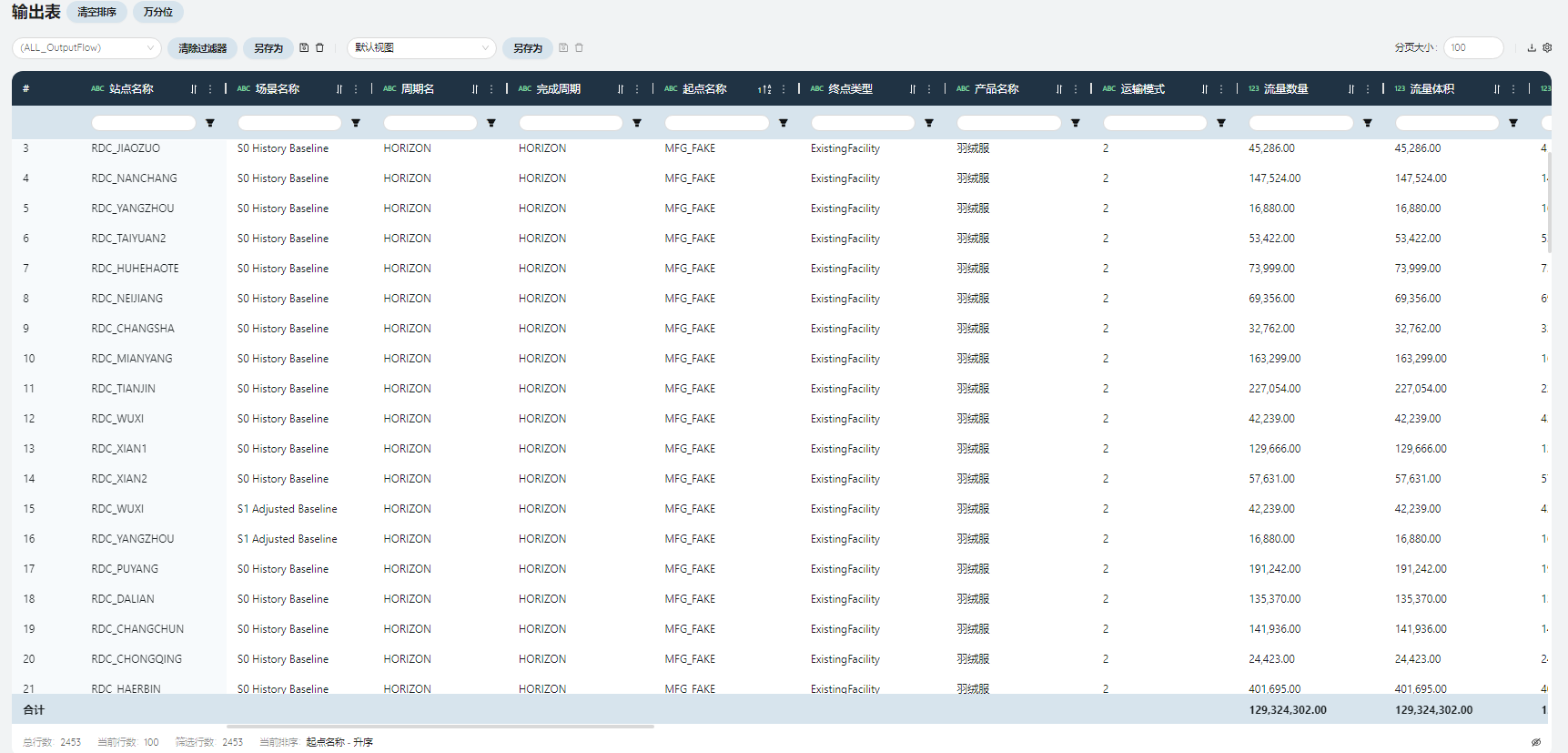
流量数量
流量流向是Scatlas以模型输入表(包括策略与限制)为条件,以最小总成本为目标计算出的结果。流量数量之和是每条线路运输的货物数量之和,等于每个设施的吞吐量之和,在此场景中,刚好等于总仓出库流量的两倍。
流量体积/流量重量
根据输入表产品中的信息计算得到,等于流量数量*产品单位体积;流量数量*产品单位重量
服务距离
若已有输入表运输策略中的距离,则等于此距离;若没有,则根据起点到终点的球面距离以及迂回系数计算得到。
总运输成本
根据输入表运输策略计算得到,在此场景中,若变动成本基准为QuantityDistance,总运输成本=流量数量*(服务距离*变动运输成本+固定运输成本);
若变动成本基准为Quantity,总运输成本=流量数量*变动运输成本。
总运输成本之和是每条线路的运输成本之和,等于整个供应链网络的总运输成本。
服务时效
根据服务距离、模型选项计算得到,等于服务距离/默认行驶速度/24小时。
# 如何进行仓库布局优化?搭建GreenField选址模型。
# 模型输入
- 客户订单
与Baseline模型相同,不用修改
- 站点
与Baseline模型相同,不用修改
- 选址服务限制
根据原始数据-选址-服务要求,填写站点名称、距离、百分比。
站点名称
根据站点表建立组,每一个区域对应一个站点组SET。
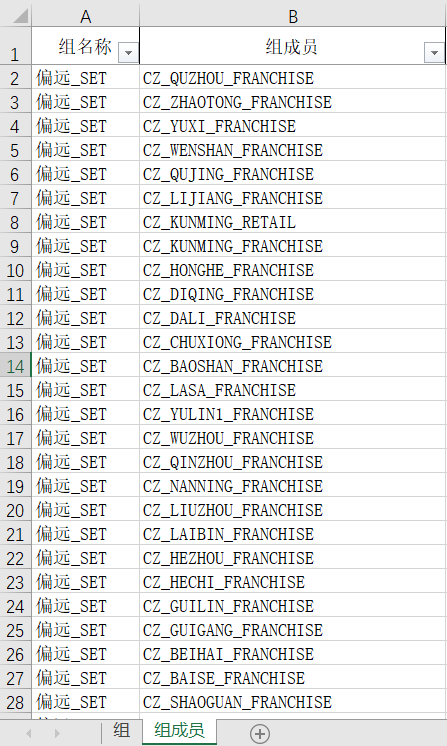
如何批量建组?操作步骤如下

 ①点击左侧功能栏中的小立方体(见右图)
①点击左侧功能栏中的小立方体(见右图)
②选择导出数据(见右图)
③在输入表中勾选数据组,包括组和组成员
④点击导出,打开导出的Excel
⑤在组sheet中,组类型填写Set,组实体填写Sites(代表站点表),组名称按下图提示按区域填写
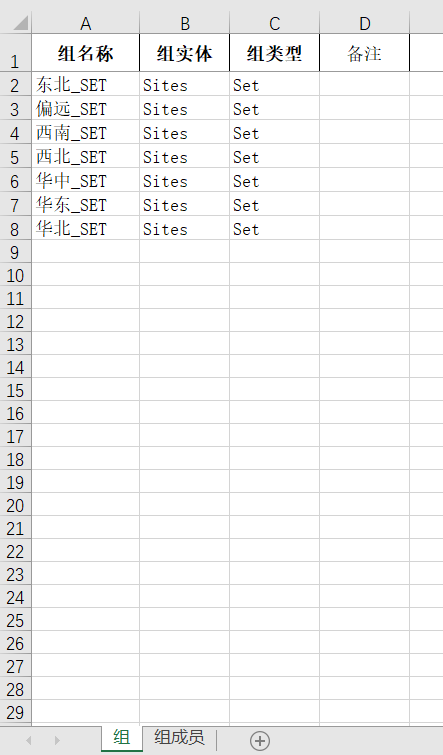
⑥在组成员sheet中,组成员即原始数据-门店信息中的门店名称,组名称填写所在区域,然后在每一个区域后加上_SET,这样组和组成员就对应起来了
⑦回到Scatlas的模型界面,再次点击左侧功能栏中的小立方体
⑧选择导入数据,导入刚才填写好的Excel
⑨在左侧功能栏选择组,看到七个区域对应的组已经建立完成
站点名称填入每一个组的组名即可。
距离
根据原始数据-选址-服务限制中,平均时速*服务时间计算得到。
百分比
即选址-服务限制中的需求满足率。
- 模型选项-选址优化
选址数量填写25,考虑已有站点选择false。
# 模型输出
填写完输入表之后,点击左侧功能栏进入在线任务列表,点击新增任务,选择算法“选址分析(GF)”,点击添加,模型开始运行。算法会在满足选址服务要求的条件下,找到发往客户段的流量乘以距离最小的选址方案。
- 选址汇总
选址汇总表展现了GreenField选址之后的对于新方案预测的总流量、总流量乘以距离与加权服务距离等信息。

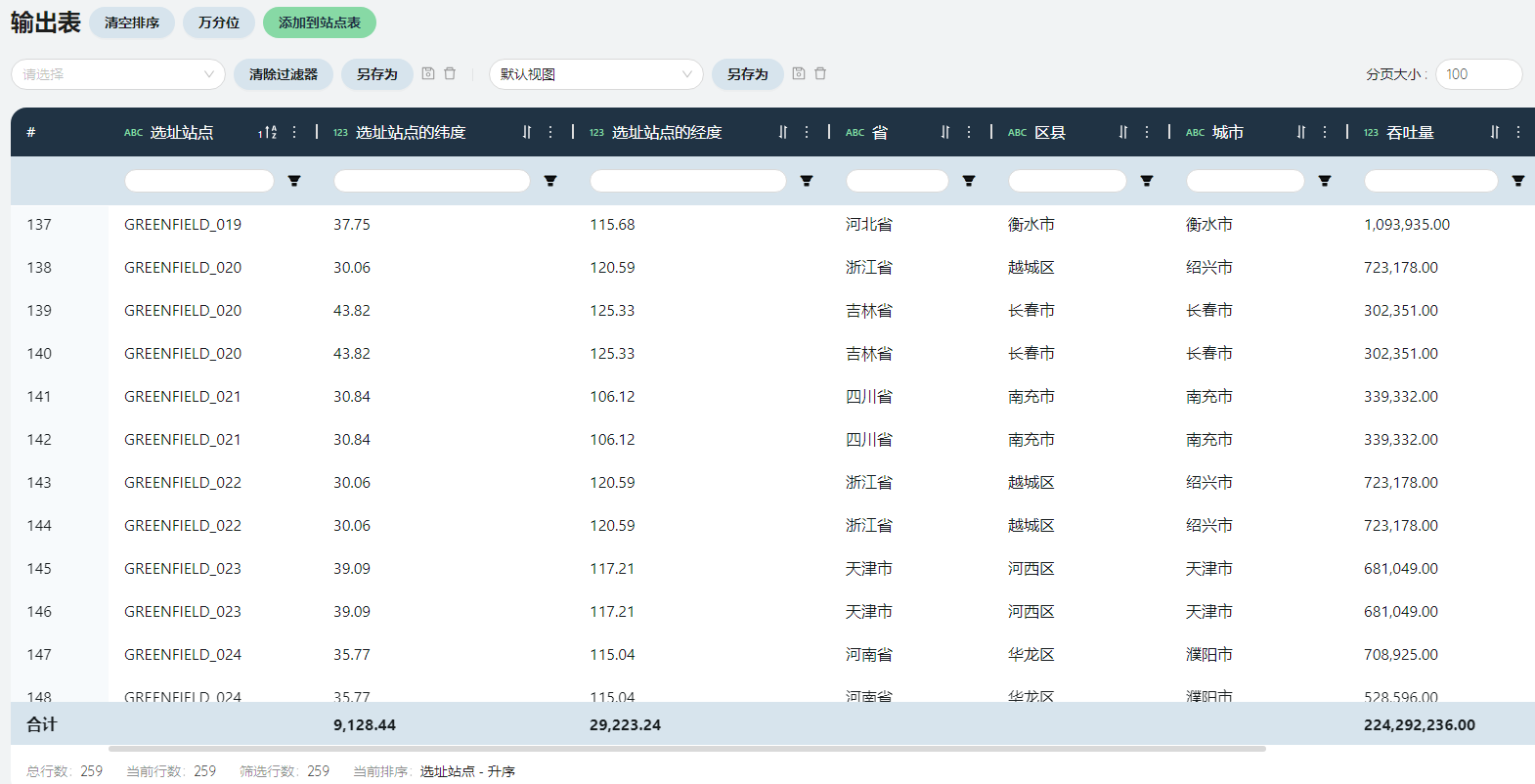
- 选址站点汇总
展现了25个选址站点的位置以及预测的吞吐量信息。
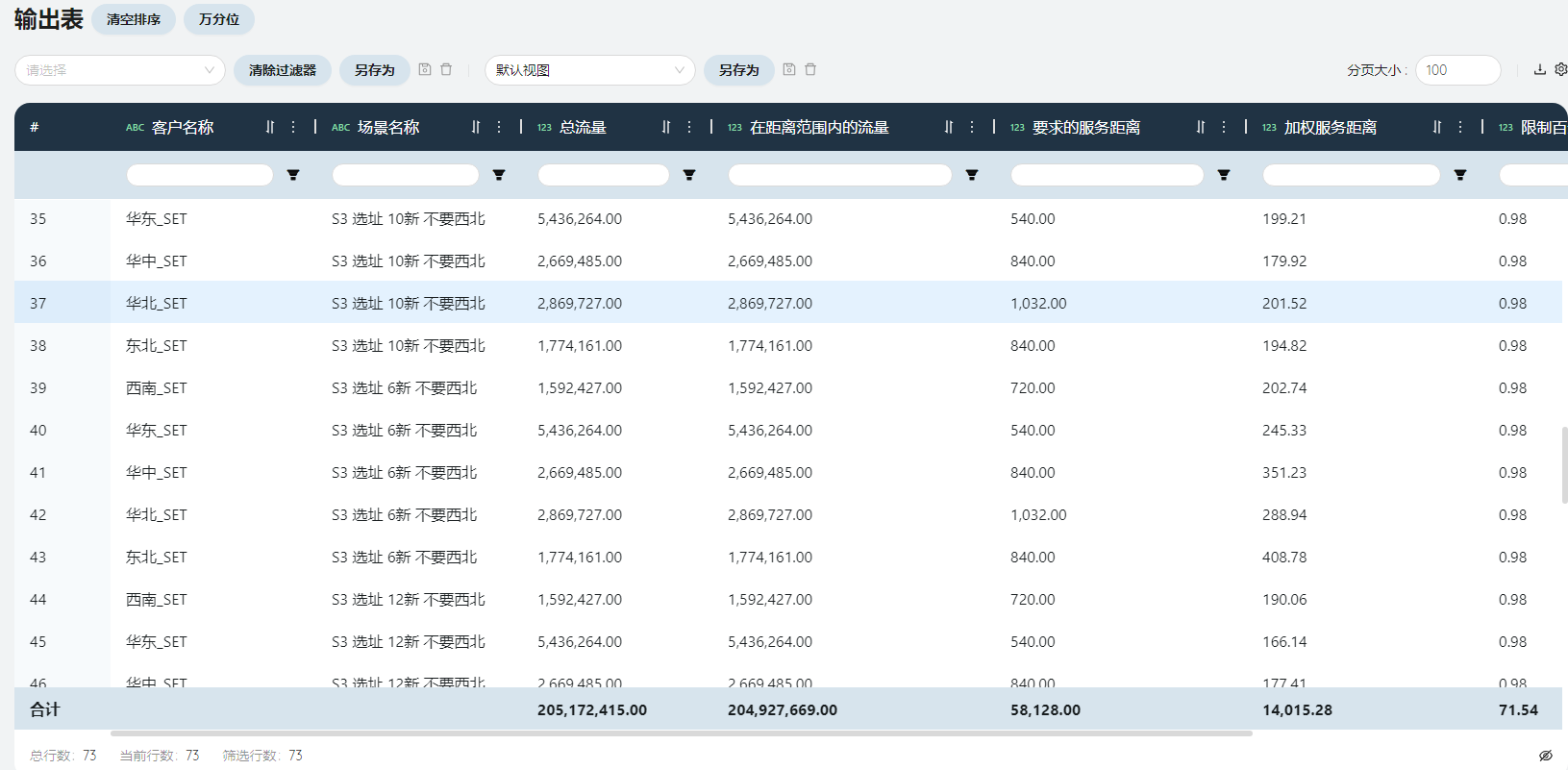
- 选址服务汇总
展现了有服务要求的客户预测的服务距离、距离范围内的流量等信息,为方案可行性作初步评估。
- 选址流量
展现了预测的发往客户段的流量数量、服务距离。

# 如何预测优化结果?搭建Scenario。
为了预测选址方案的优化细节,可以将选址站点添加到站点表,在新站点的基础上运行网络优化得到优化结果。
# 模型输入
- 站点
在选址站点汇总界面,点击上方的添加到站点表按钮,选择替换当前过滤条件筛选值。
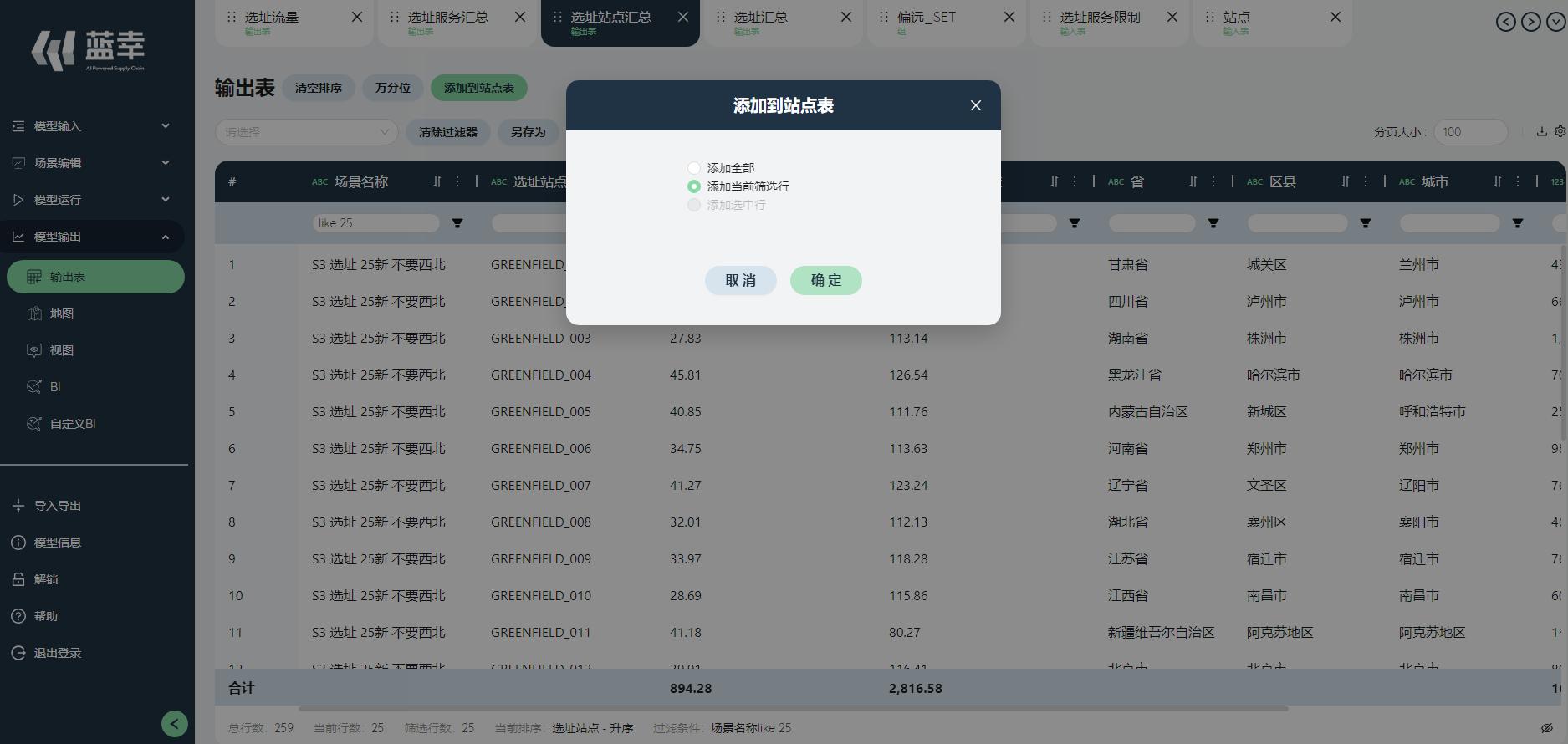
回到站点表,发现新的选址站点已经添加。
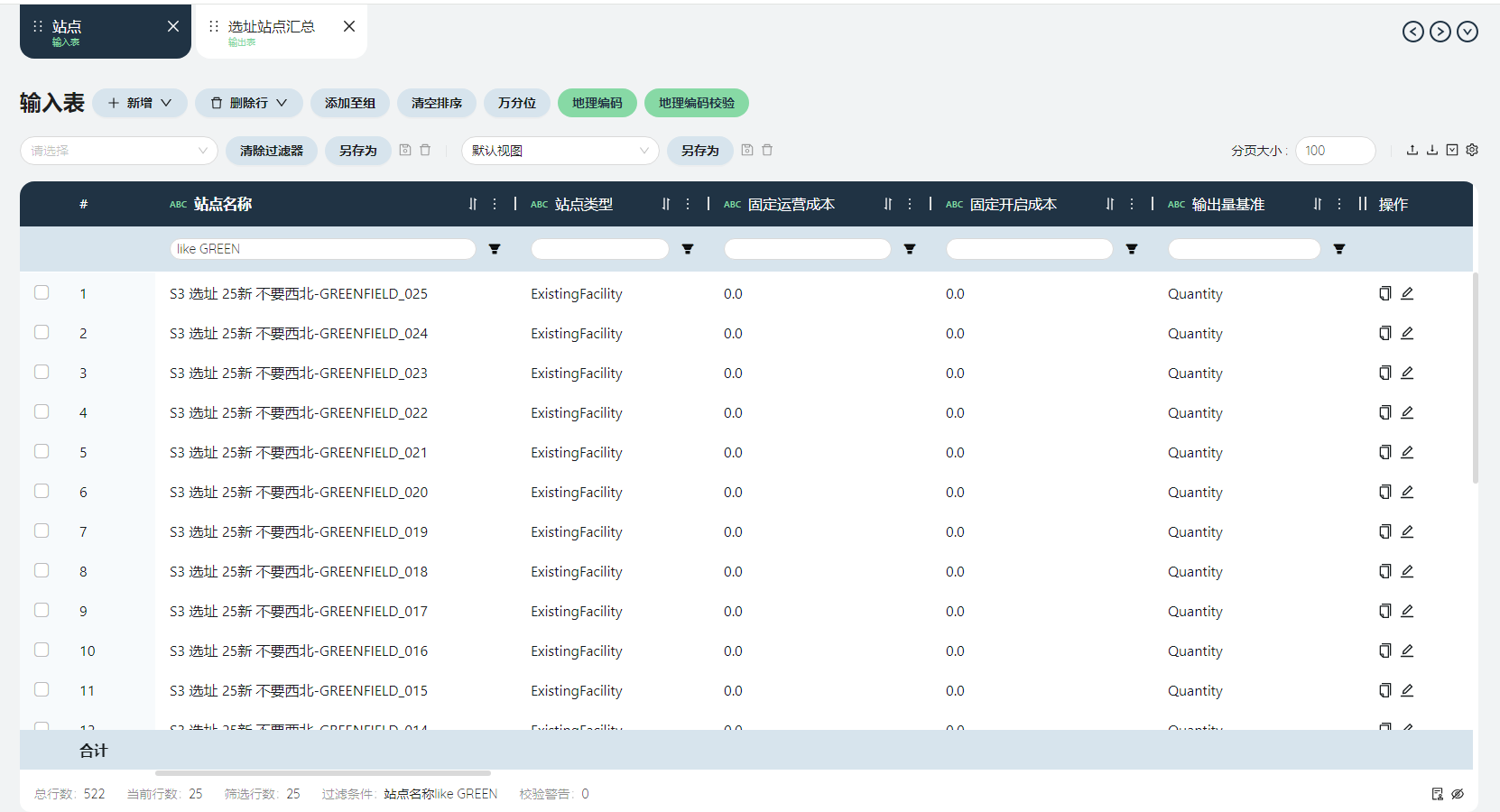
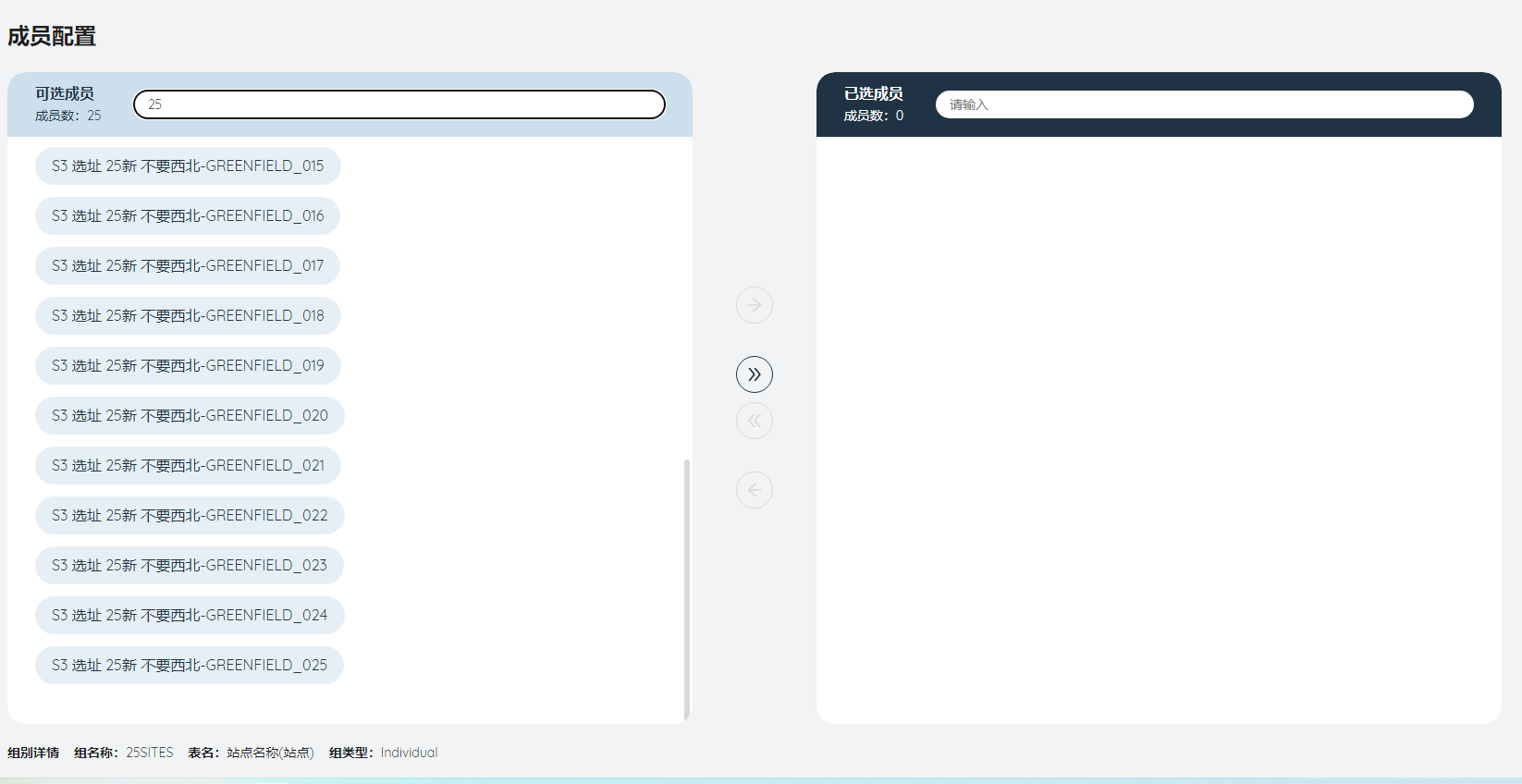
给25个新选址站点建组,命名为25SITES,类型为Individual。
- 采购策略
在选址流量界面点击导出,在Excel中将除了起点名称和客户名称之外的列全部删除,客户名称重命名为站点名称,新增产品名称列,全部填充值“羽绒服”。
在采购策略界面点击导入,导入方式选择添加,将从新选址站点到客户的线路采购羽绒服全部添加到采购策略。
添加一条从NDC总仓到组25SITES采购羽绒服的线路。
- 运输策略
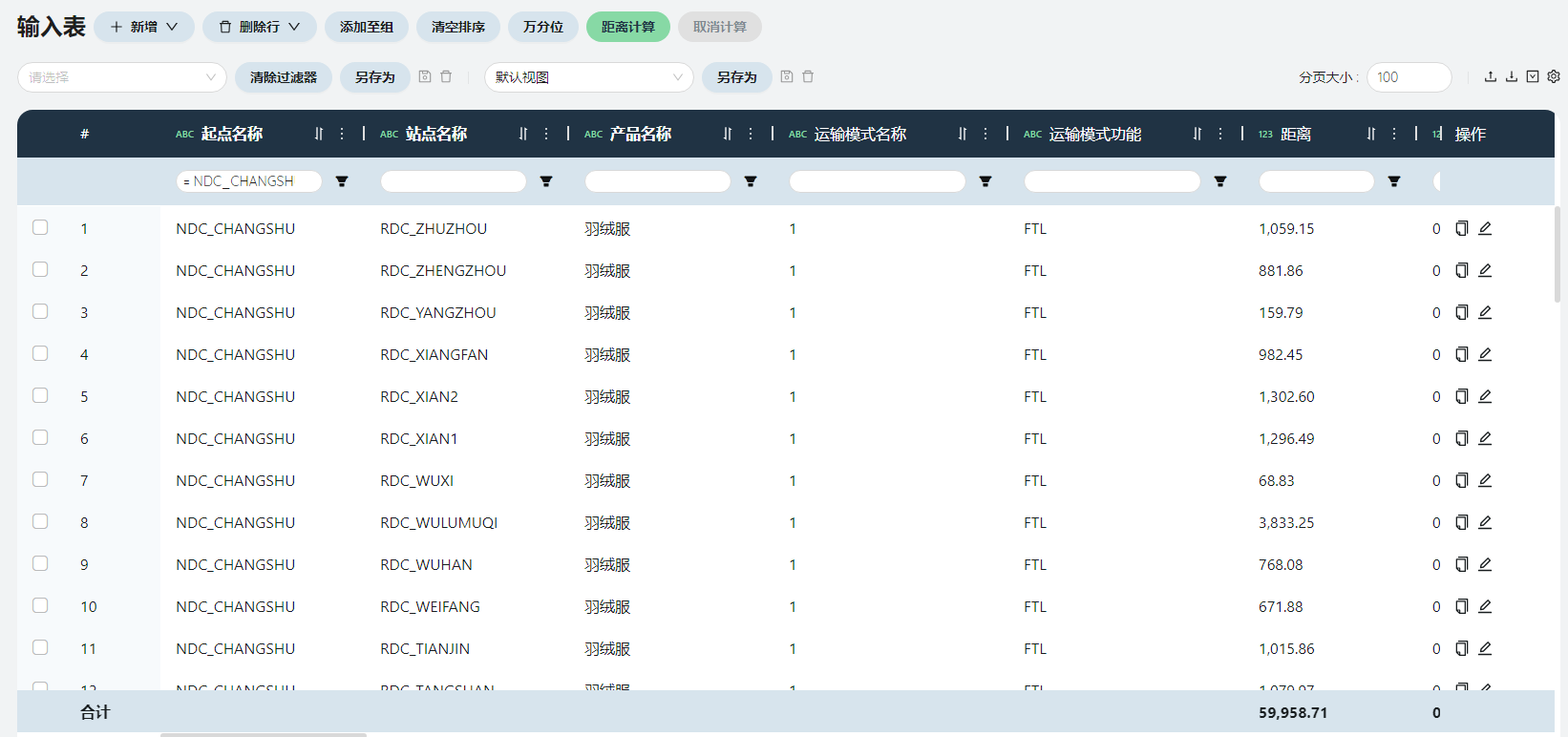
在选址流量界面点击导出,在Excel中将除了起点名称和客户名称之外的列全部删除,客户名称重命名为站点名称,新增产品名称列,全部填充值“羽绒服”,新增运输模式名称列,全部填充值“2”,新增运输模式功能列,全部填充值“LTL”,新增变动运输成本、变动成本基准、固定运输成本三列,按照分仓-门店的运输成本填写。
在运输策略表添加从NDC到每一个新选址地点的运输线路,若选址城市与原来相同,运输成本也取原来的值,若选址城市与原来不同,运输成本取总仓-分仓的预测值(如下图)。
- 库存策略
添加一条新选址站点可以存放羽绒服的策略。

- 场景
在左侧功能栏,选择场景,点击新建场景,按下图提示输入场景名,点击提交。


新建场景项C1
在左侧功能栏,选择场景项,点击新建场景项,按下图提示输入场景项名,点击提交。


编辑场景项C1
关联表选择站点,站点名称根据筛选条件:”like RDC”筛选

点击另存为过滤器,命名为RDCs,

筛选器选择RDCs,字段选择状态,运算符选择“=”,值选择“Exclude”。

点击保存,看到保存成功弹窗。
新建场景项C2-1
命名为“C2-1 采购策略 分仓起点exclude”。目的是让模型不考虑从原来的RDC出发的线路。
编辑场景项C2-1
按下图提示填写,筛选条件为起点名称“like RDC”。
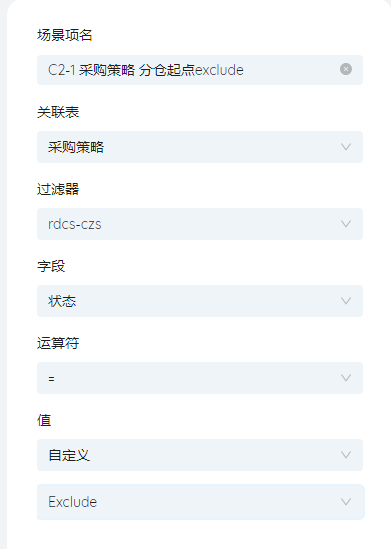
新建场景项C2-2
命名为“C2-2 采购策略 分仓终点exclude”。目的是让模型不考虑以原来的RDC为终点的线路。
编辑场景项C2-2
与C2-1类似,筛选条件为站点名称“like RDC”。
新建场景项C3-1
命名为“C3-1 运输策略 分仓起点exclude”。目的是让模型不考虑以原来的RDC为起点的线路。
编辑场景项C3-1
与C2-1类似,筛选条件为起点名称“like RDC”。
新建场景项C3-2
命名为“C3-2 运输策略 分仓终点exclude”。目的是让模型不考虑以原来的RDC为终点的线路。
编辑场景项C3-2
与C2-1类似,筛选条件为终点名称“like RDC”。
新建场景项C4
命名为“C4 库存策略 分仓exclude”。
编辑场景项C4
按下图提示填写,筛选条件为起点名称“like RDC”。
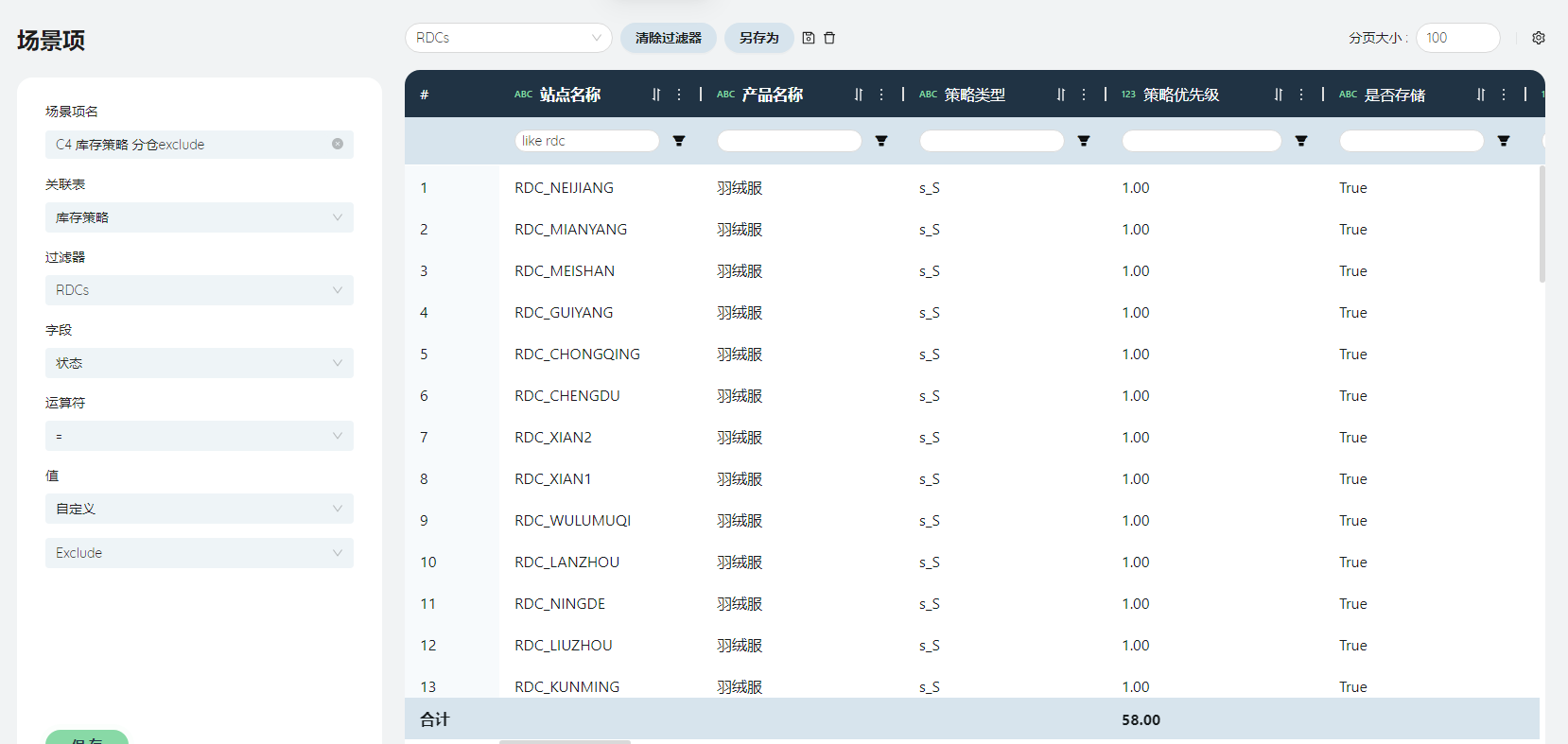
按下图提示编辑场景“预测优化结果”。
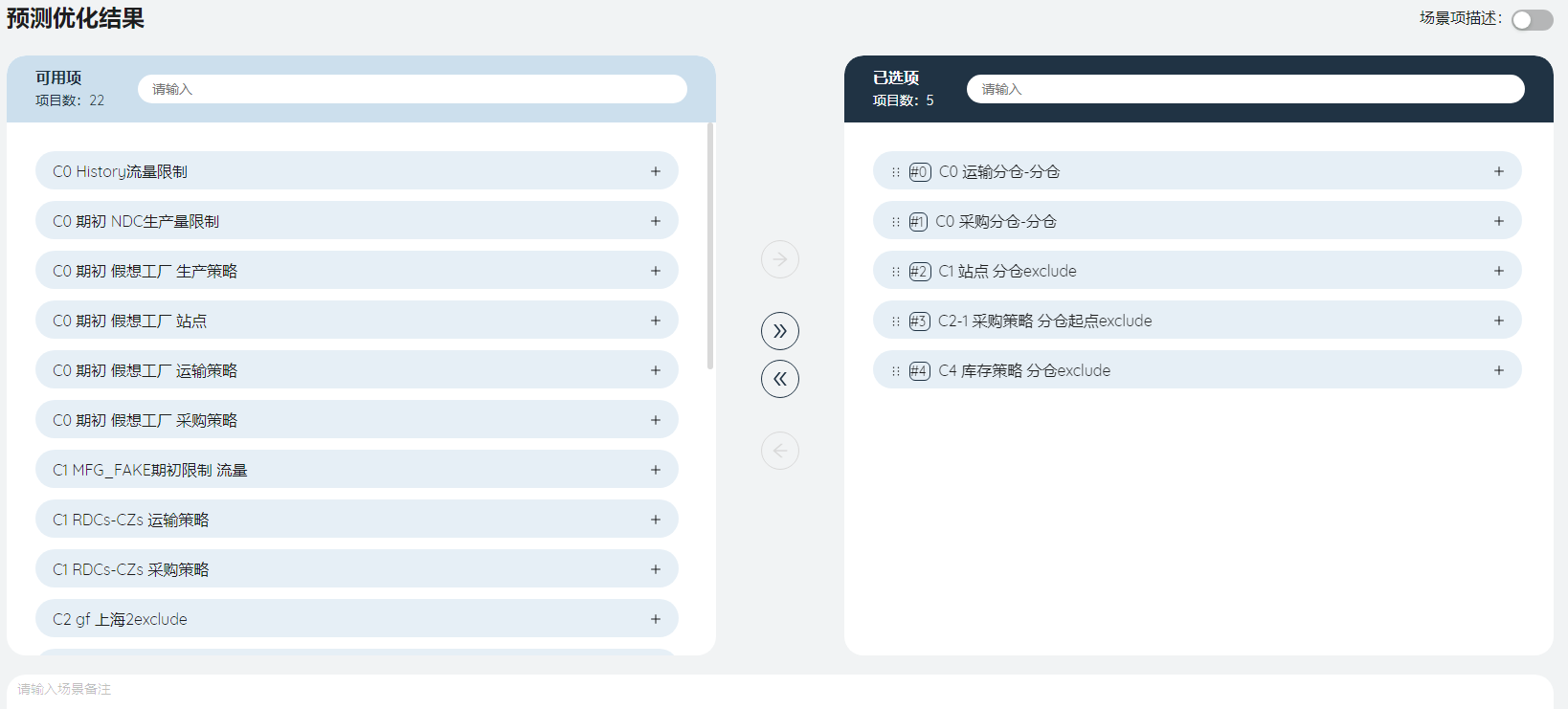
# 模型输出
在在线任务列表运行场景:预测优化结果。
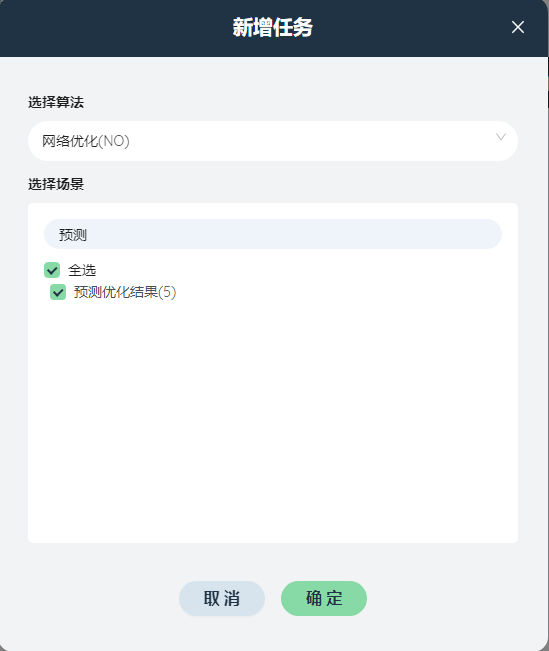
导出输出表:运输流量。在模型外分析优化结果。
# 方案分析及对比
对从Scatlas中导出的运输流量表做数据分析。
一般包括以下三个方面:仓网布局对比、成本构成对比、服务水平对比。
可能有各个运输层级、国家/地区/仓库、产品的流量、运输成本、服务距离、服务时效等关键指标。
# 仓网布局对比
使用Scatlas自带的地图工具绘制Baseline和优化后模型的仓网布局地图。
- 绘制Baseline的仓网布局地图:
点击左侧功能栏的地图,点击新建地图按钮,地图名称填写“Baseline”。

点击提交。进入地图编辑界面。
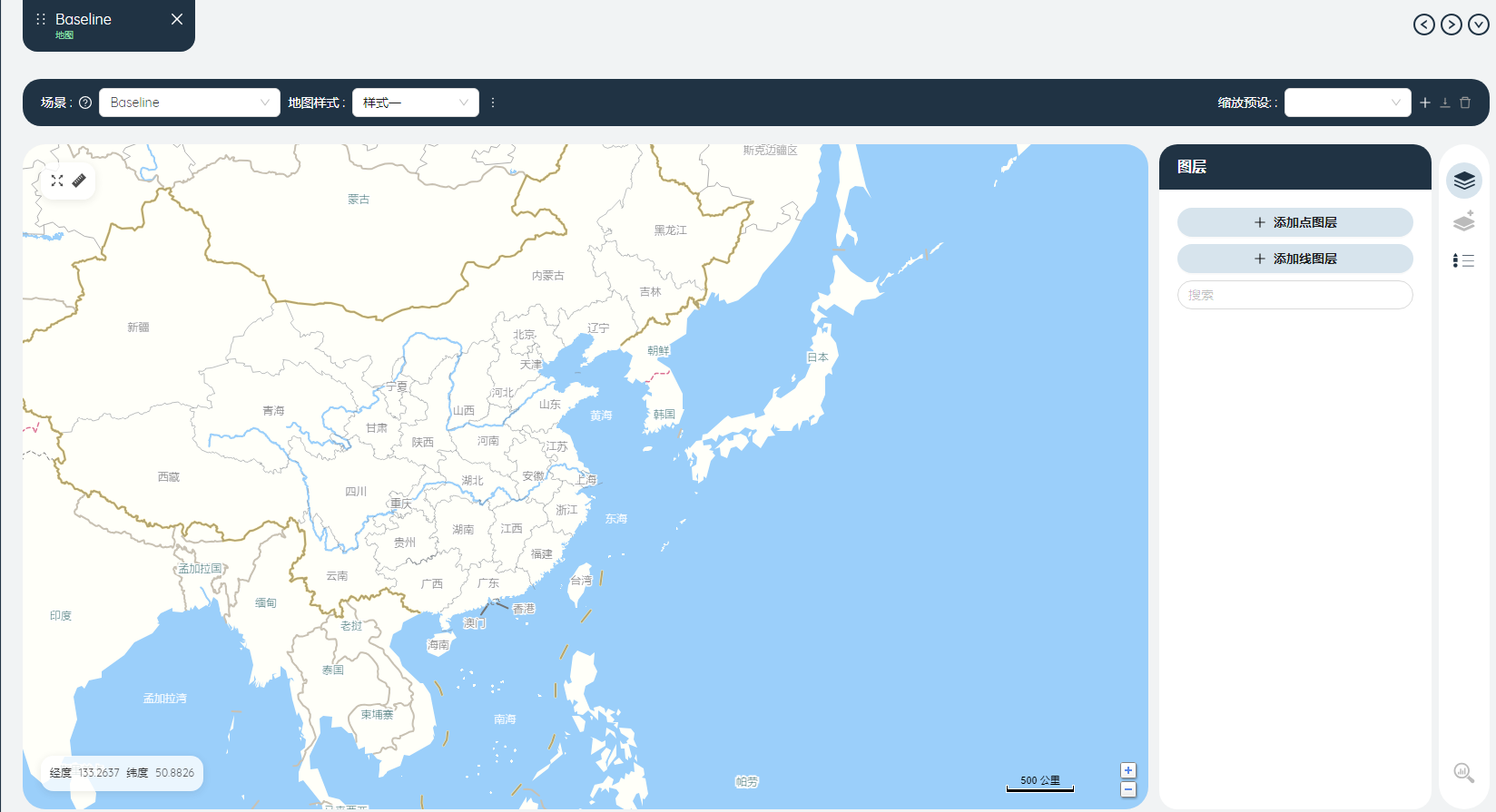
先在地图上添加站点信息,点击“添加点图层”按钮,点击“展示数据”按钮。
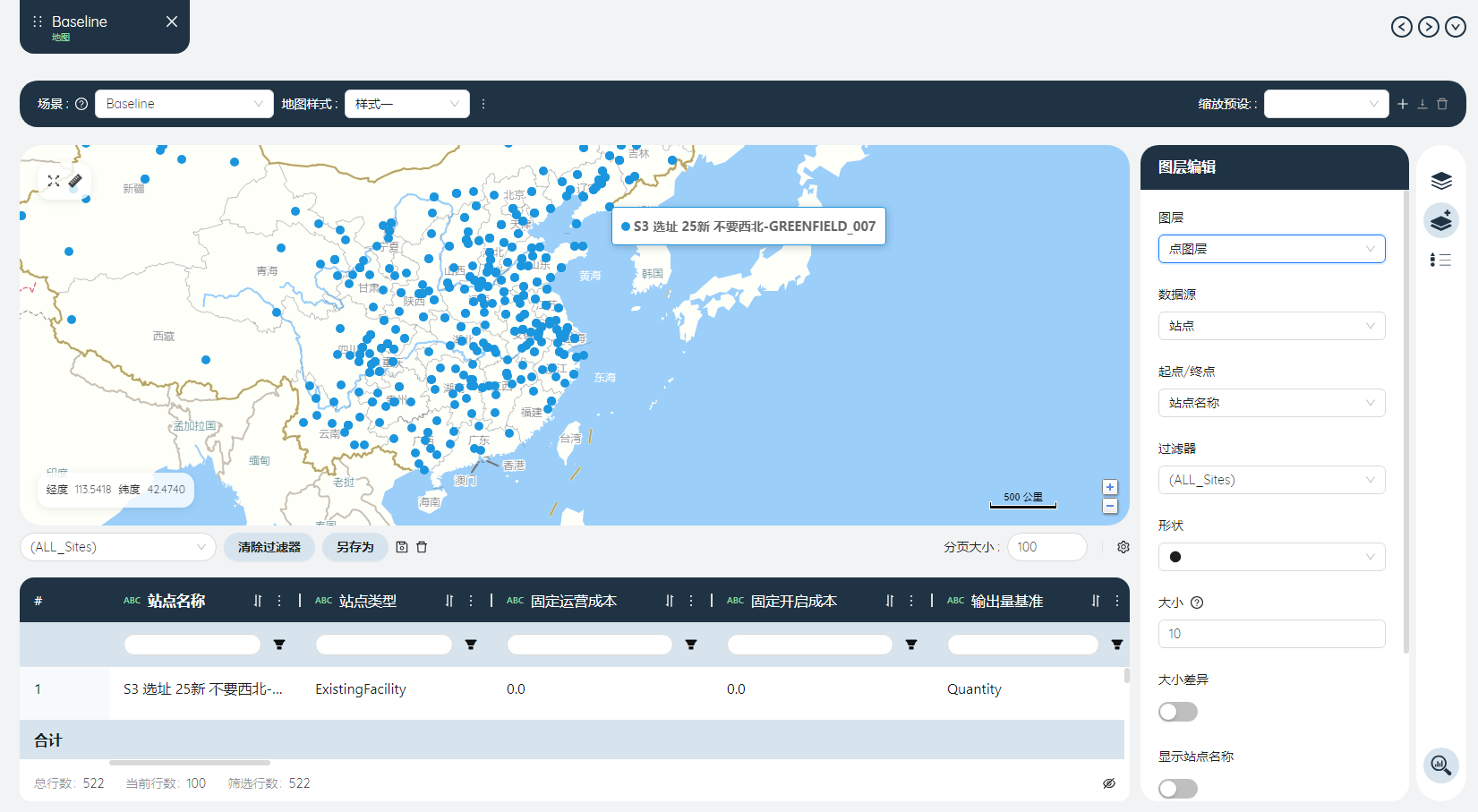
新增点图层
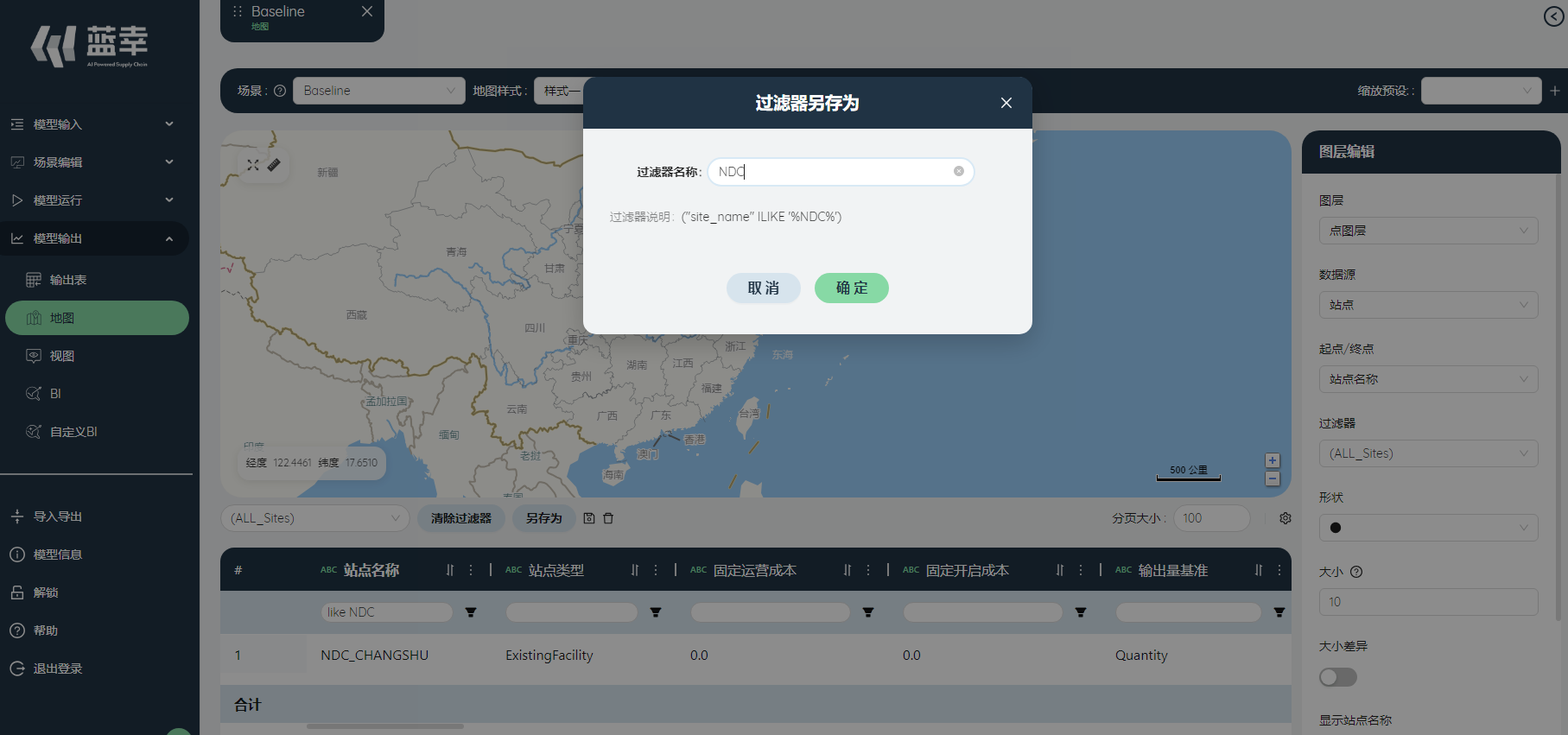
在筛选框输入NDC,点击过滤器另存为,命名为“NDC”,点击提交。
筛选器选择NDC,将点图层重命名为NDC,点击√。
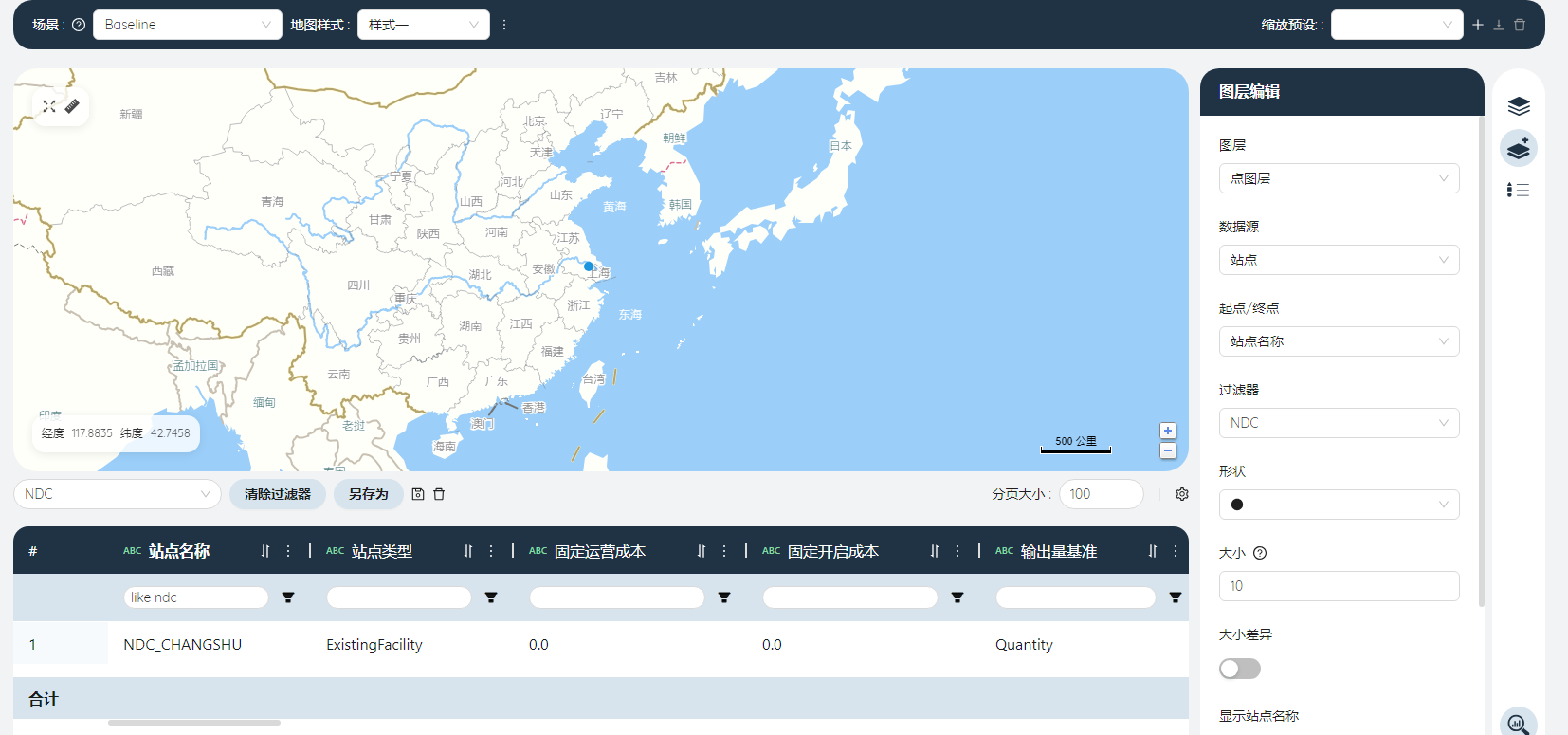
在图层编辑器中,形状选择三角,大小填写15,颜色选择红色。
可以看到地图中常熟总仓所在的位置出现了一个红色小三角。
按照下图提示,用相同的方法新增点图层:RDCs,标记为蓝色小方块。
新增线图层
场景选择Baseline,起点名称筛选为NDC,站点名称筛选为RDC,另存为筛选器“NDC-RDC”。
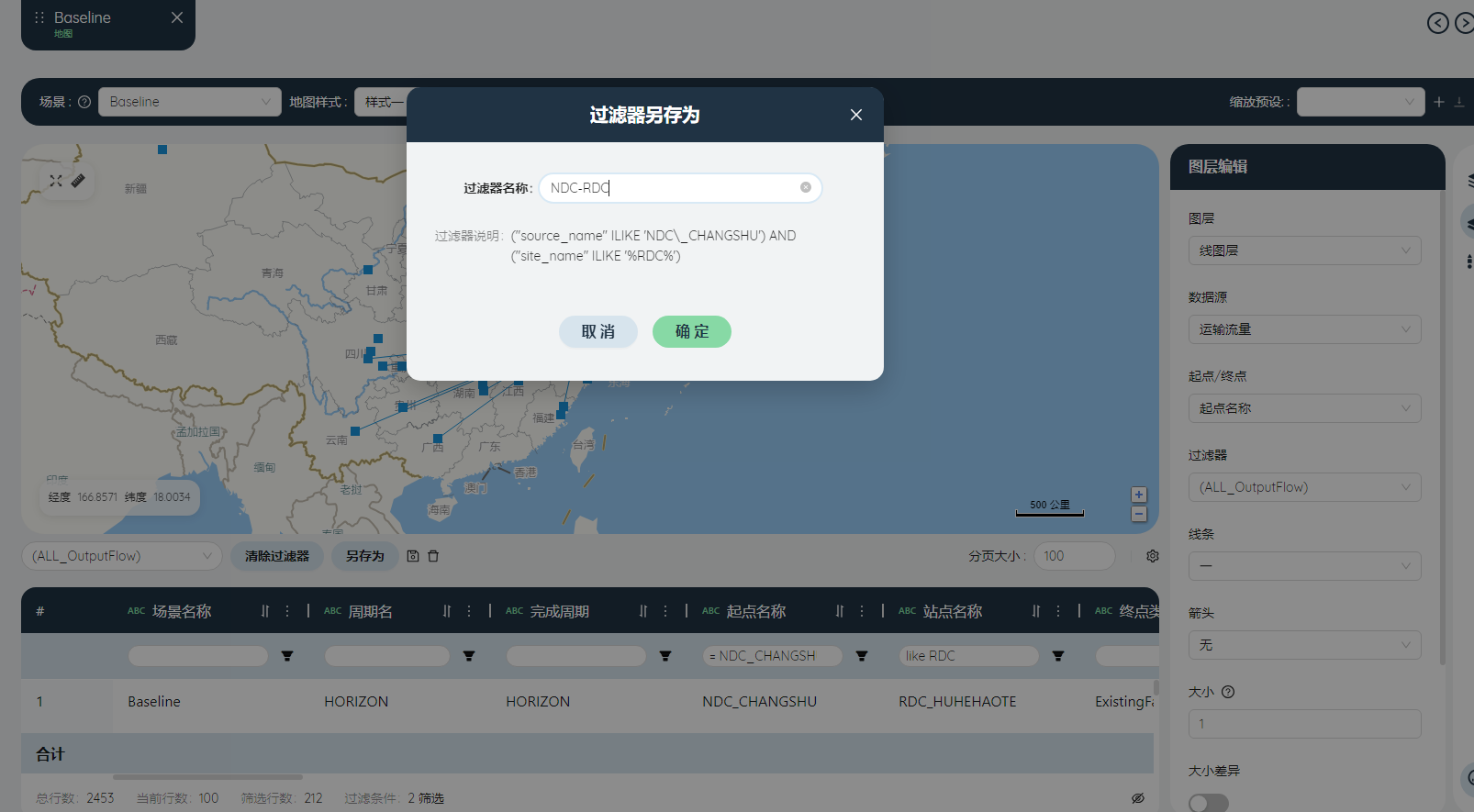
颜色选择红色,线图层重命名为NDC-RDC,点击√。
按照下图提示,用同样的方法新建图层“RDC-CZ”。
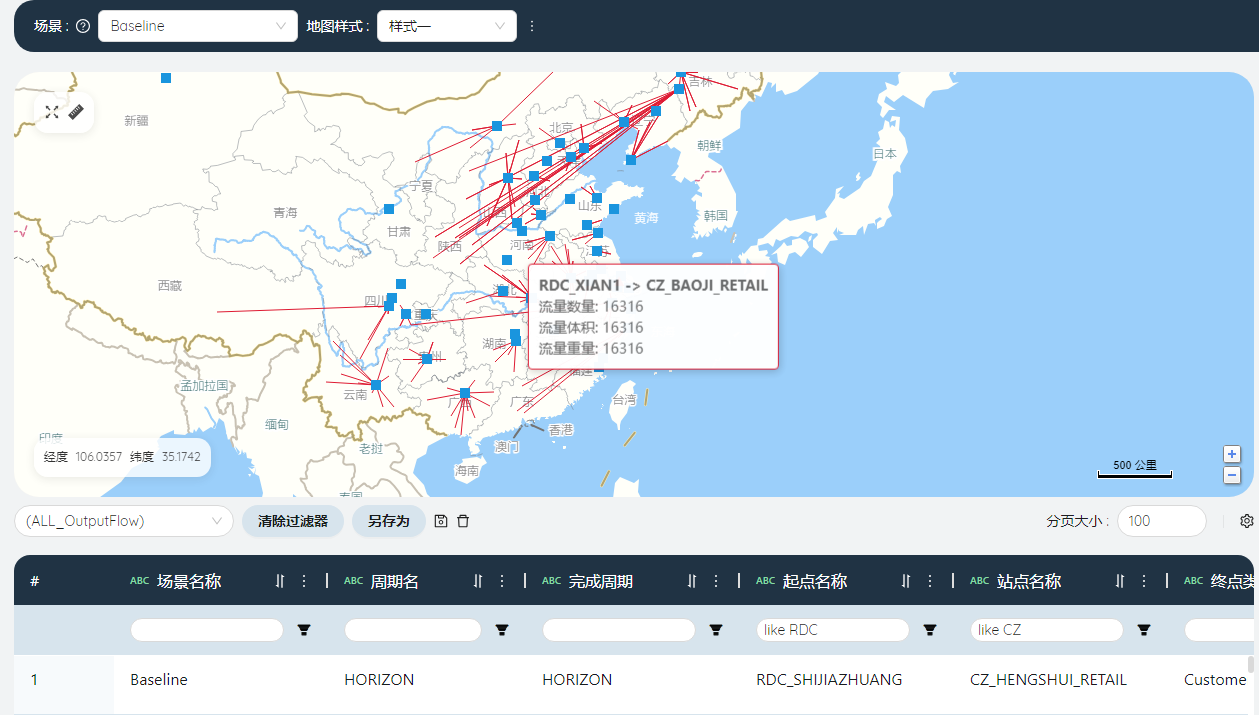
Baseline的仓网布局图完成了。
- 绘制优化后的仓网布局地图
新建地图,命名为“优化后仓网布局“。
新增点图层
场景选择“预测优化结果”,点击添加点图层,按下图提示建立新选址站点图层。
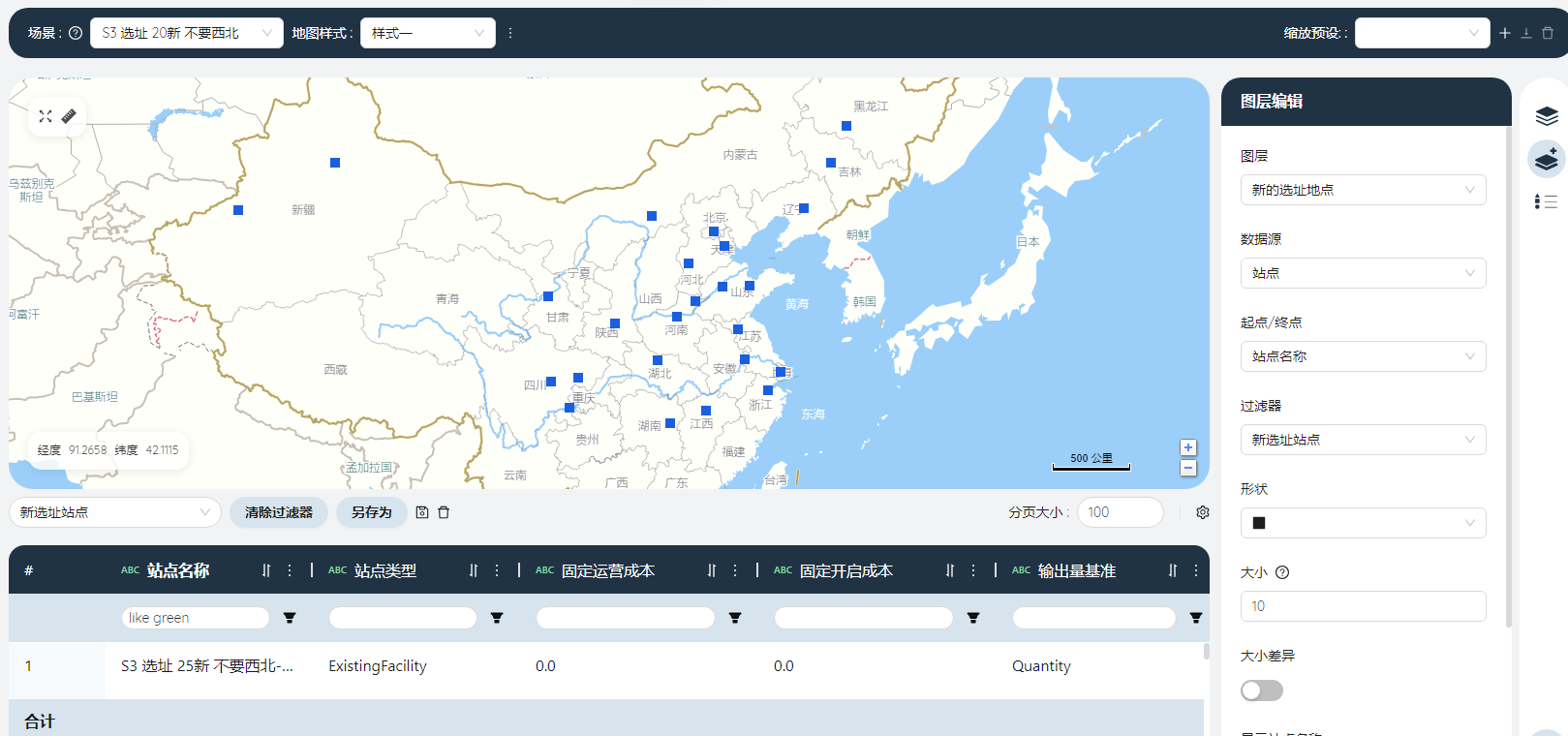
新增线图层
筛选出运输流量表中从NDC到新选址站点的线路,按下图提示建立线图层。
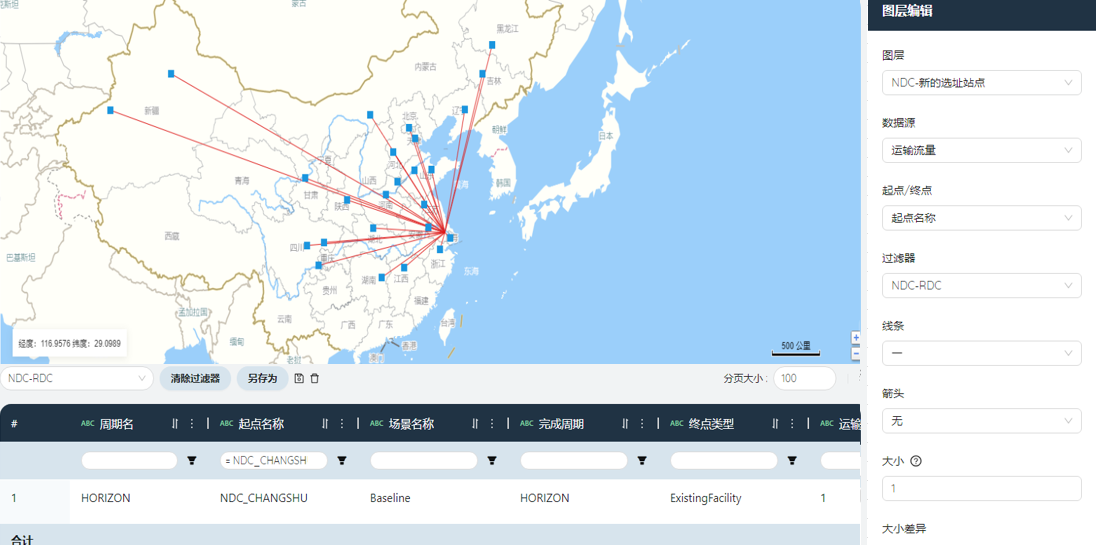
筛选出运输流量表中从新选址站点到门店的线路,按下图提示建立线图层。
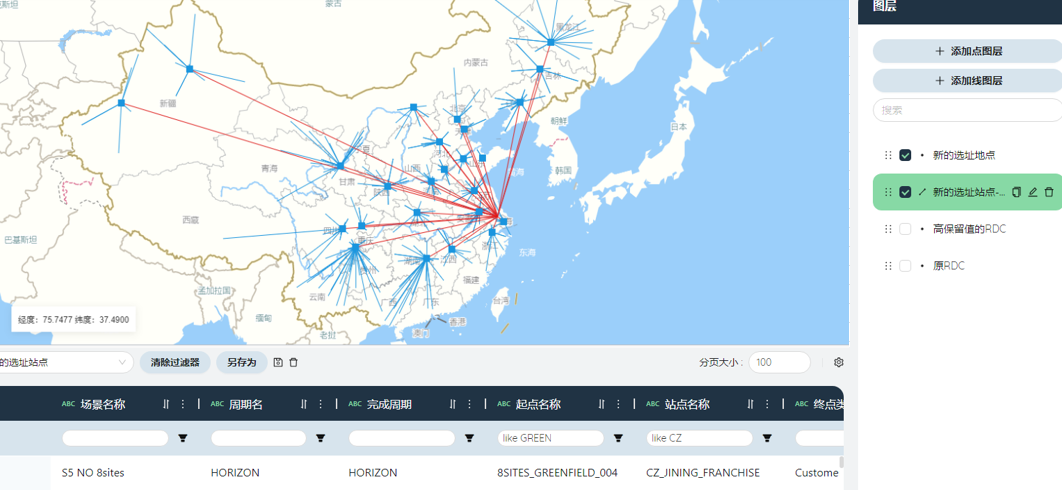
优化后仓网布局地图绘制完成。
- 优化前后仓网布局对比:
Baseline的仓网布局图(58DC)
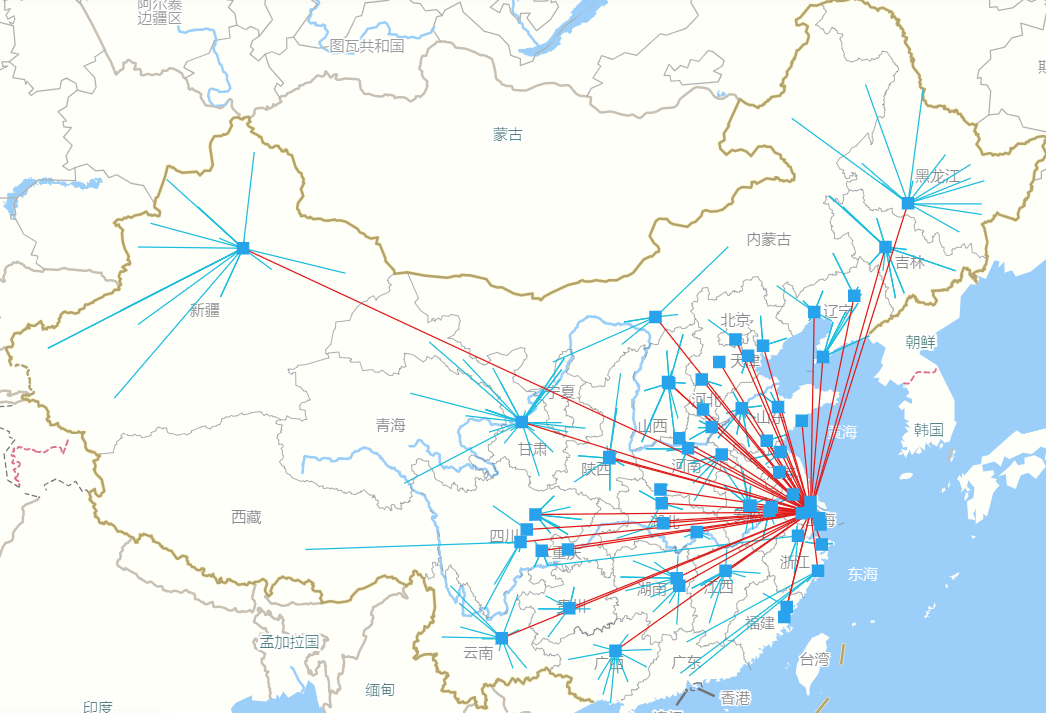
优化后的仓网布局图(25DC)
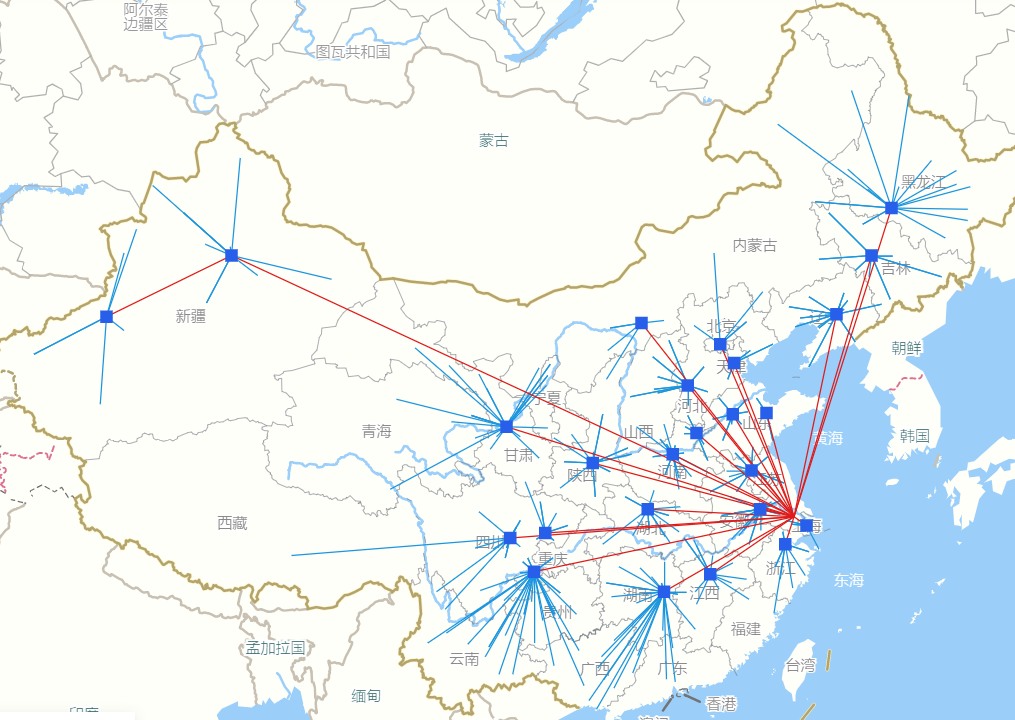
优化后仓库数量减少了33个。
在优化后方案的25个仓库中,包括原有仓库 18个,新增仓库
18个,新增仓库 7个。
7个。
# 成本对比
优化后总成本下降了3.24%,约98.7万元。
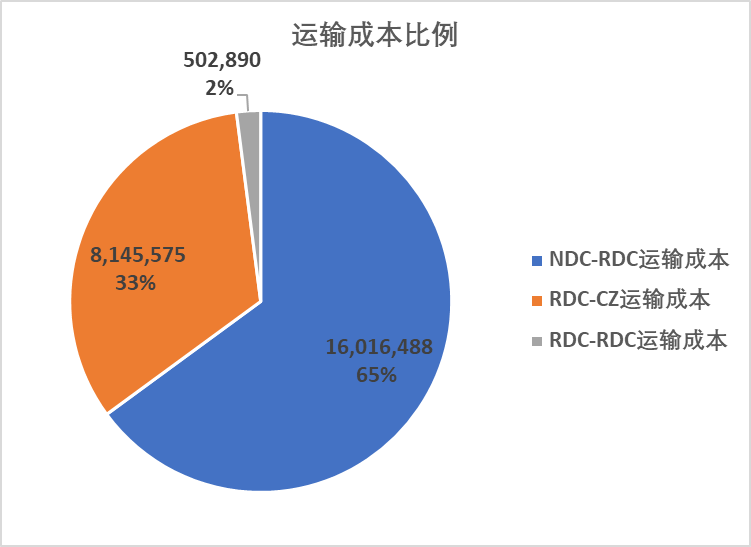
其中NDC-RDC(总仓-分仓)段运输成本下降了4.99%,约111.5万元;RDC-CZ(分仓-门店)段运输成本上升了1.54%,约12.5万元。
# 服务水平对比
Baseline现状中西北和西南地区的服务水平没有达到98%的要求线。
优化后所有地区的服务满足率都达到了要求。
# Mock Case 2:LX Milk
# 如何反映历史现状?搭建Baseline基准模型。
# 项目范围
产销计划时间范围:2017年6月
设施概况:14处奶源地,16处工厂,55处客户
产品:1种原材料(原奶,保质期9天),20种成品种类(SKU),16种长保产品,4种短保产品(保质期15天)
总需求量:78,484吨
运输方式:汽运、铁运、海运(原奶和短保产品过期作废,全部采用汽运)
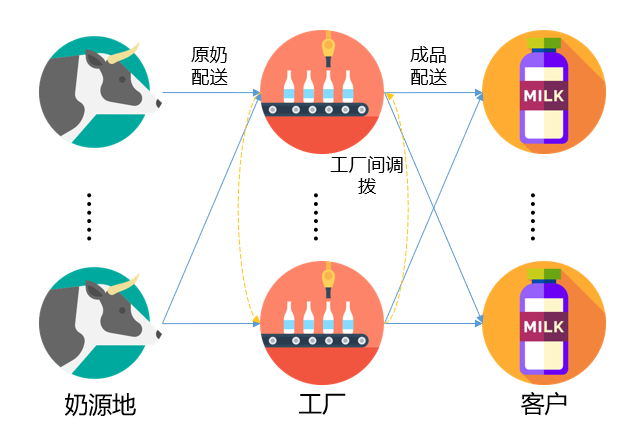
产品流动类型
原奶配送:奶源地-工厂
成品配送:工厂-客户
调拨:奶源地之间、工厂之间原奶和成品调拨
# 原始数据
# 原始数据下载
产品数据

客户位置

工厂位置

奶源供应地点

客户需求

成品各运输模式发运线路和单价
原奶调拨线路和单价

计划可用原奶

BOM原奶耗用

生产变动成本

生产批量

工艺系数

产能

手工生产计划
手工分销计划

# 模型输入
用户须知
在运行模型之前,数据以表格的形式输入。
不同的算法所需的模型输入各不相同,其中又分为必需输入和可选输入,比如NO的必需输入表为周期、产品、站点、客户订单、生产策略、采购策略、运输策略、库存策略。而S&OP(滚动生产计划)涉及的更多,包含了描述生产端所需的工作中心、生产流程、物料清单(BOM)等输入表。
接下来将介绍Baseline基准模型所需的输入表,包括使用到的字段的含义、字段的值与原始数据之间的对应关系。
- 周期
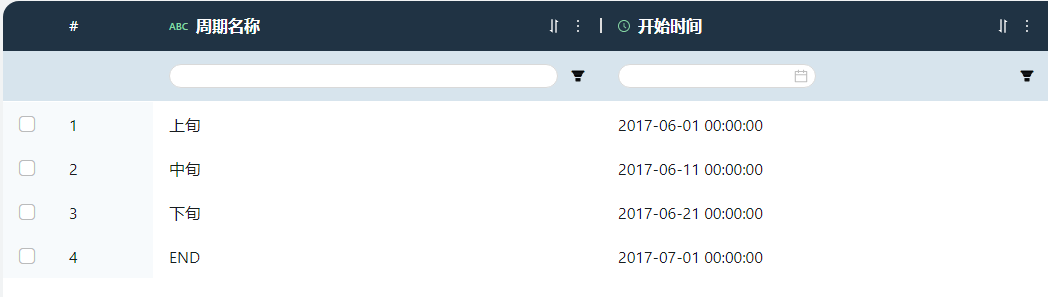
依据项目范围,从2017年6月1日上旬开始至7月1日下旬结束,分为上中下旬3个周期。
- 产品
包含产品名称、价格、保质期、产品大类、产品类别(保质期长短)等信息。
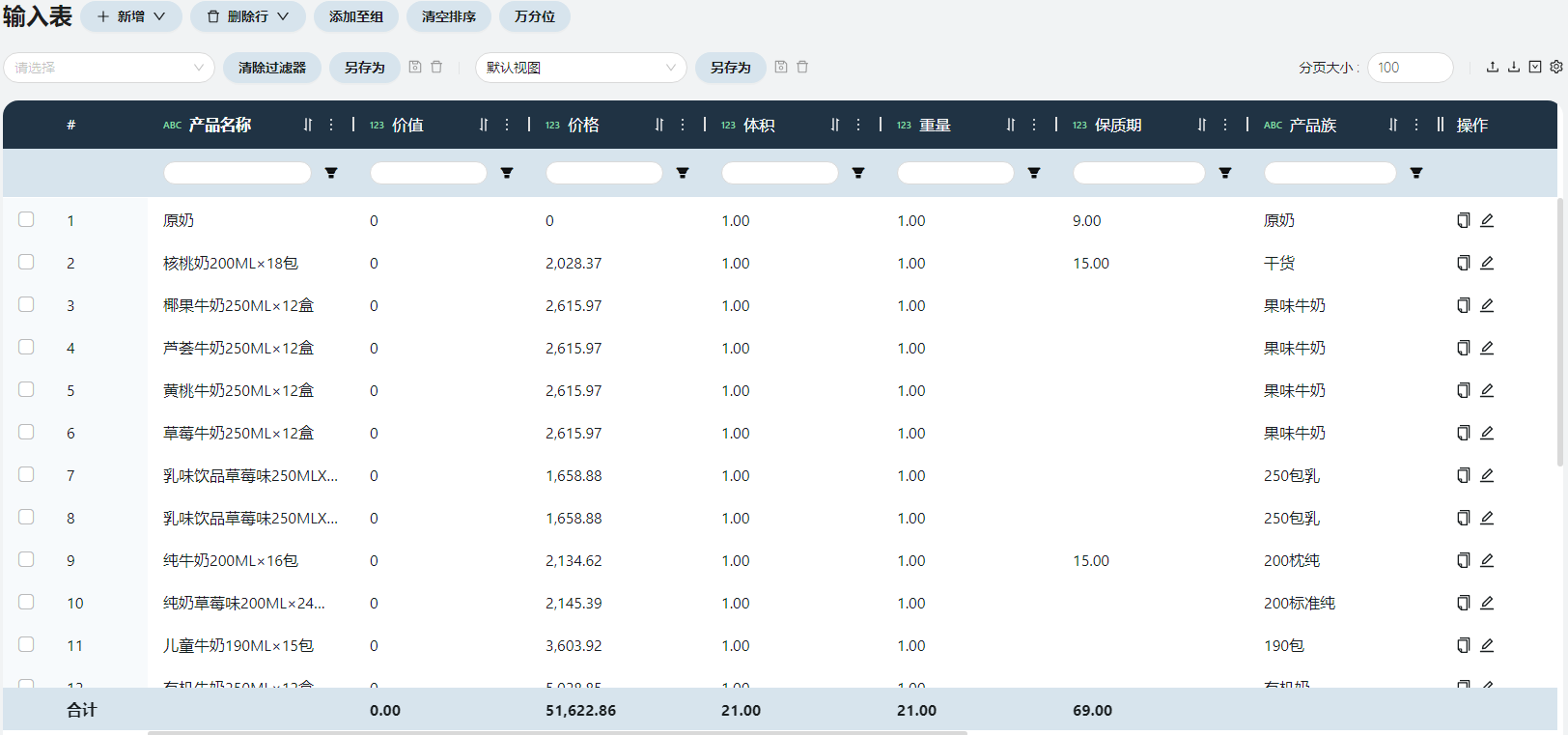
产品名称
原奶1种原材料+20种成品,共21行数据。
价格
根据原始数据-产品数据中的**产品出厂价(元/吨)**字段对照填写。
保质期
原奶保质期为9天,短保产品保质期15天,长保产品保质期不考虑。
备注
根据原始数据-产品数据中的产品大类填写(可不填)。
自定义1
根据原始数据-产品数据中的产品类别填写(可不填)。
- 站点
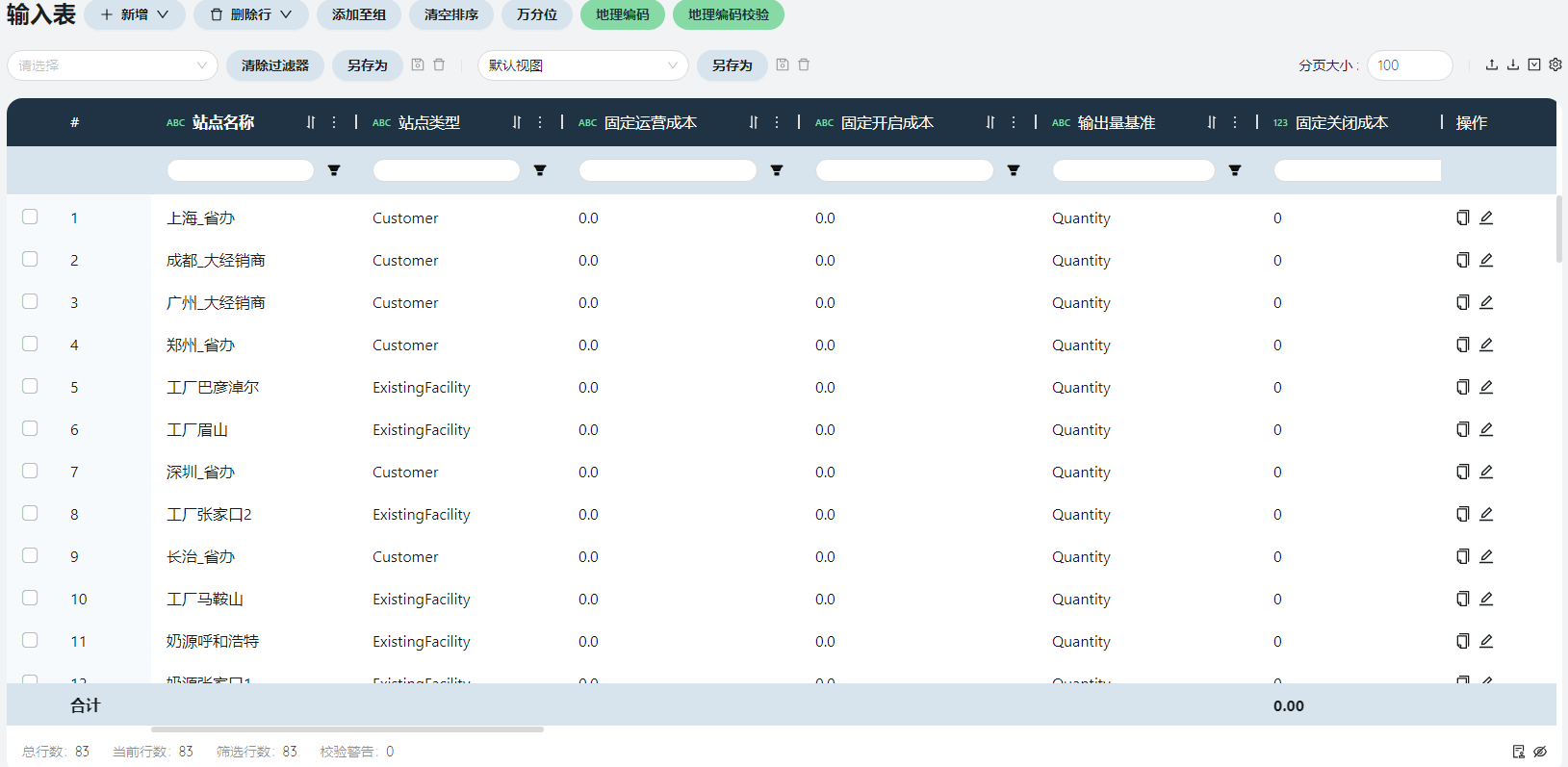
站点名称
1个Dummy假工厂(用于生产、运输期初库存)+14个奶源+16个工厂+52个省办/大经销商客户,共83条数据。
站点类型
假工厂、奶源、工厂为ExistingFacility,客户为Customer。
城市、省份
根据原始数据-客户位置、工厂位置、奶源供应地点填写对应的省市信息。
纬度/经度
站点表的省市信息填写完成后点击地理编码自动获取。
站点族
奶源、工厂、省办客户、大经销商客户。
- 工作中心
工作中心一般指产线或车间,包含固定运营成本(可设置为阶梯)、限制值基准等信息。
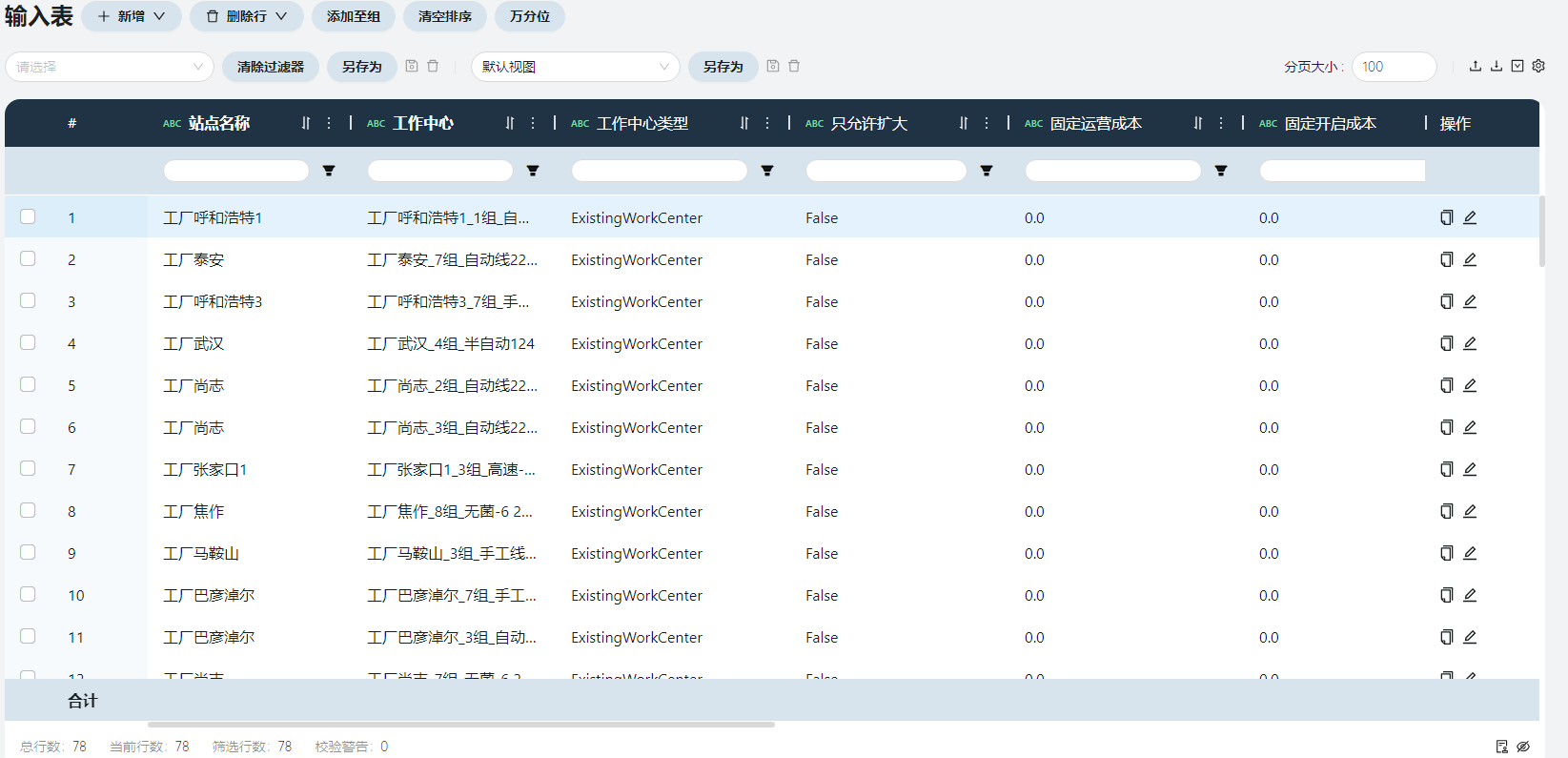
工作中心
根据原始数据中的产能表的工厂名称、设备组名称字段填写,命名规则是<工厂名称>_<设备组名称>
站点名称
填写工作中心对应的工厂
限制值基准
用于指定生产流程中限制值的单位基准,此场景下每个工作中心都为Hour,生产受时间限制。
- 工作中心多周期
可以在此分周期设置每个工作中心的固定运营成本、开启/关闭成本、碳排量等信息。
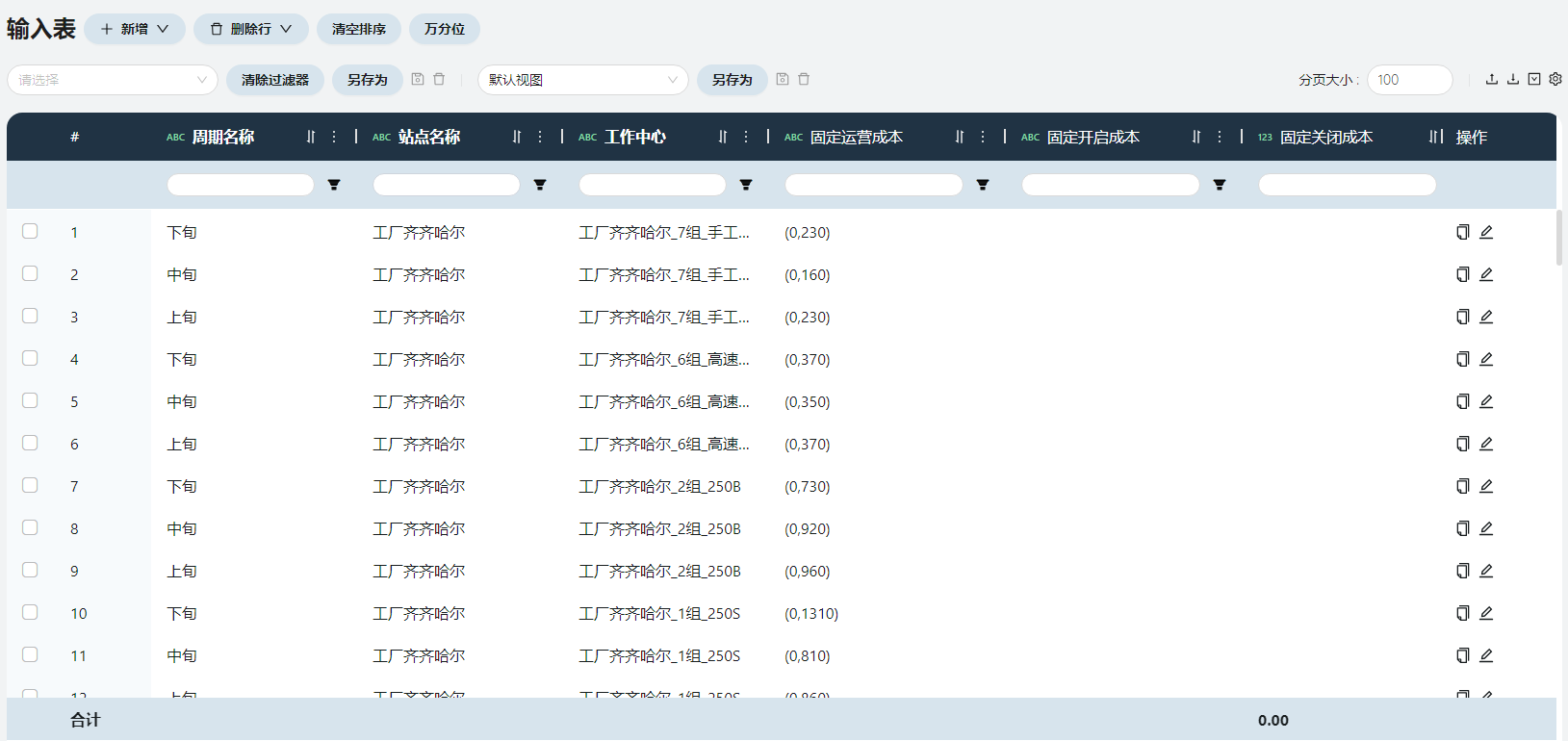
周期名称
上旬/中旬/下旬
固定运营成本
一般填写格式为:(第一阶梯的运营成本,第一阶梯的吞吐量上限),(第二阶梯的运营成本,第二阶梯的吞吐量上限) 。在这个场景中通过吞吐量上限设置每个周期每个设备组的产能上限。
原始数据中的产能就是每个工作中心的吞吐量上限,填写在( 0 , 这里 )。
- 客户订单
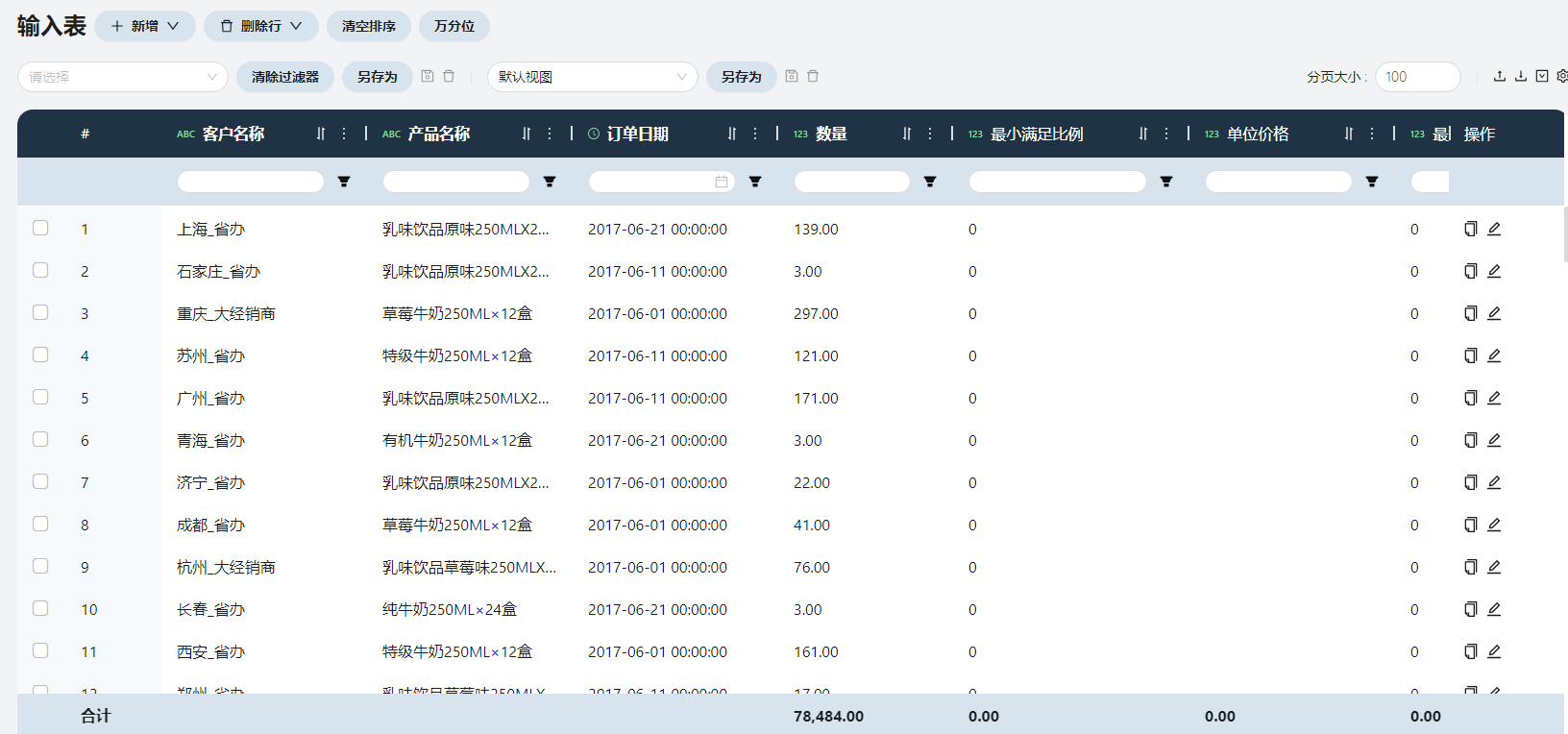
根据原始数据-客户需求得出。
订单日期
填写上中下旬的每个周期首日,例如:上旬即2017/6/1。
- 生产策略
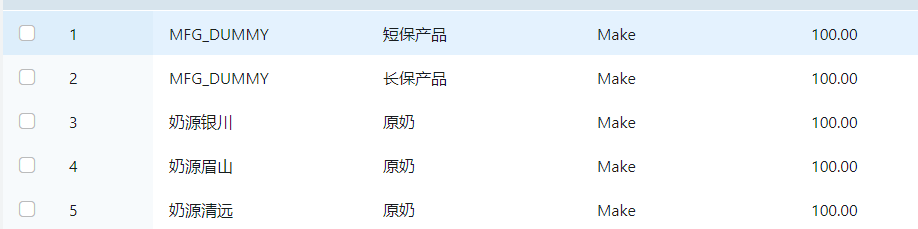
奶源生产原奶,工厂生产成品,Dummy假工厂生产成品(短保/长保产品)。
- 物料清单
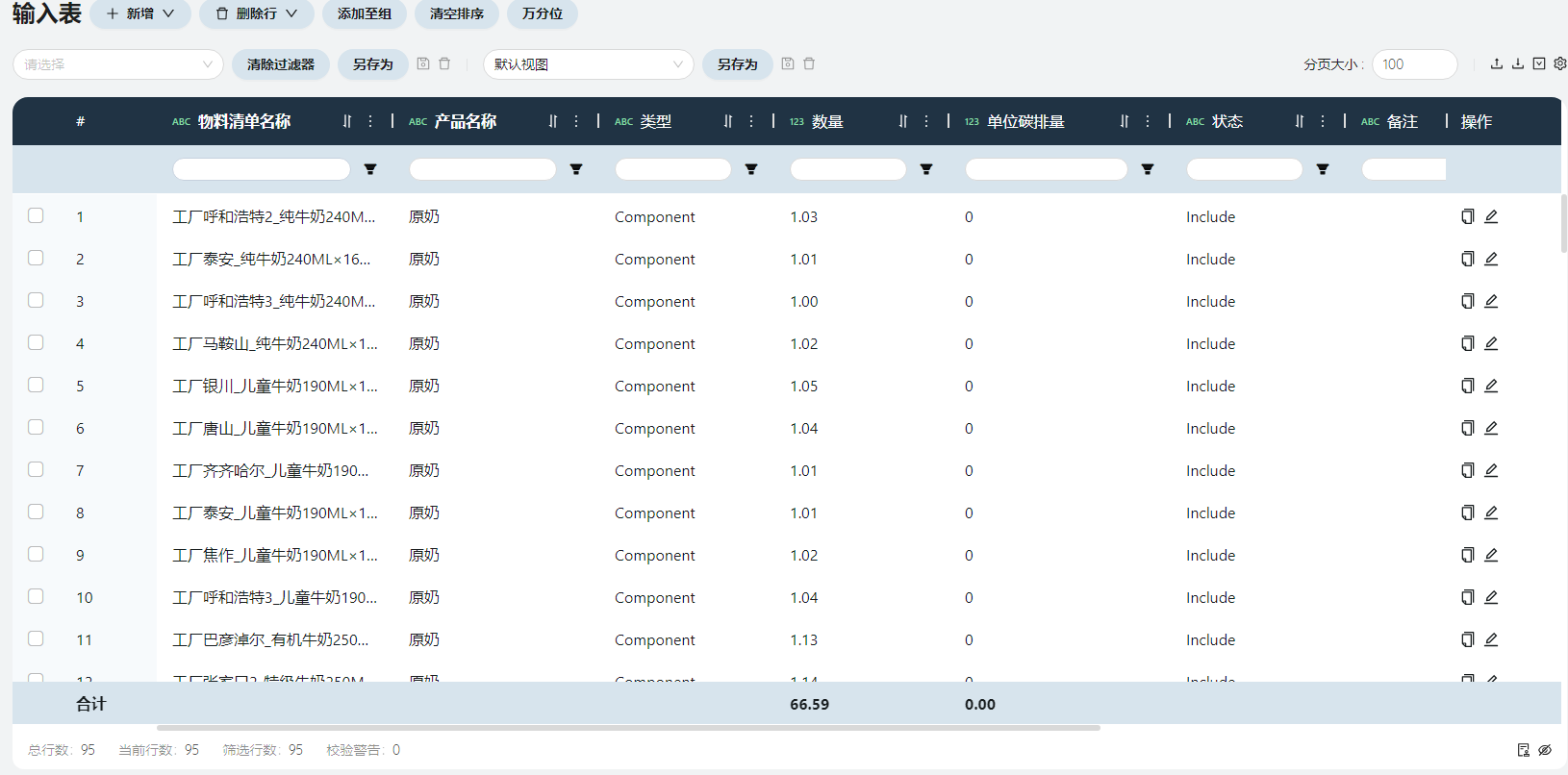
物料清单名称
物料清单(简称BOM)是某个工厂生产某种产品的原材料清单,命名规则为<工厂>_<成品名称>_BOM。
产品名称
填写BOM的原材料,在此场景中,所有产品的原材料都只有原奶一种。
数量
根据原始数据-BOM原奶耗用中的**单吨成品所需原奶(吨)**得到。
- 物料清单匹配
该表存在是为了将BOM名称与周期、站点(生产地)、产品关联起来。
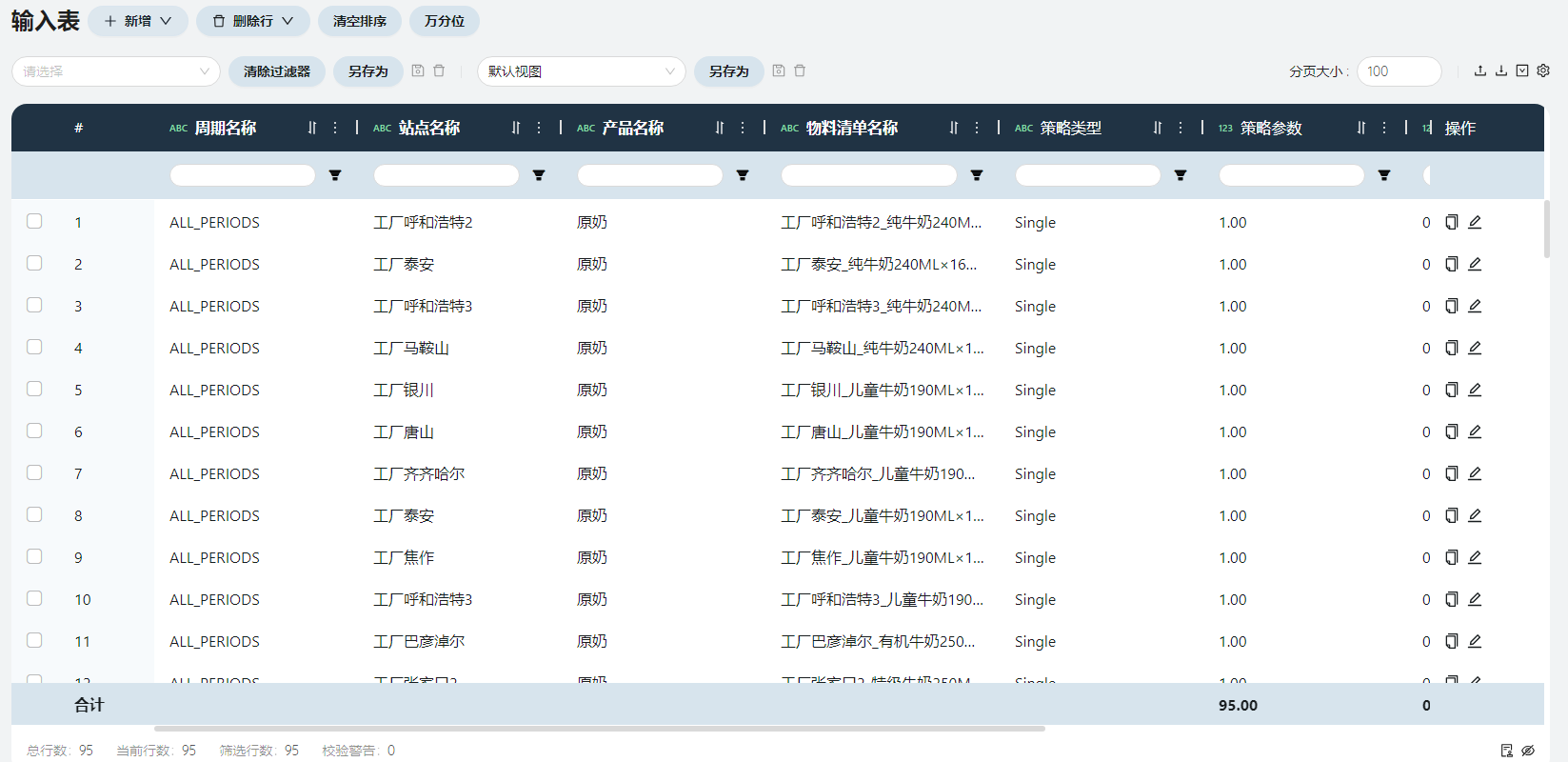
周期名称
每个周期工厂生产产品的物料清单都一样,不需要区分,填写ALL_PERIODS。
物料清单名称
物料清单(简称BOM)是产品的原材料清单,每个工厂生产同一产品的物料清单名称不同。
- 生产流程
生产流程展示了工序的相关信息,一个工序一行,也就是每个周期每个工作中心生产每种产品的流程的属性,包括流程中每个工序的工作顺序、可变生产工序成本、单位工序生产小时数等信息。
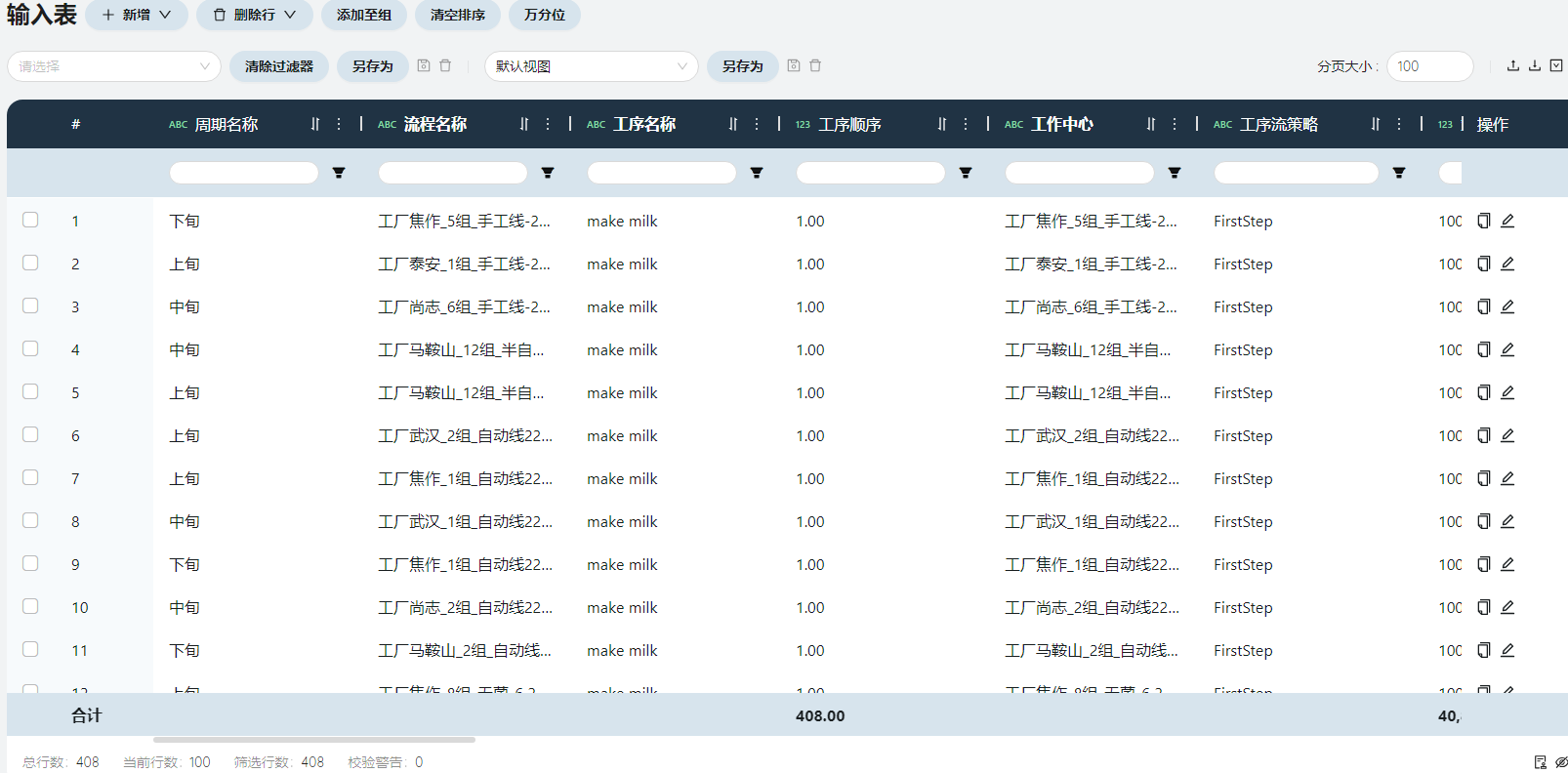
周期名称
上旬/中旬/下旬。
流程名称
每个设备组生产每种产品的流程名称,命名规则为<工作中心>_<产品名称>_PROCESS
工序名称、工序顺序
每个流程的工序都只有一步:make milk,顺序自然是1。
工作中心
填写流程名称中的<工作中心>,为了将流程与工作中心关联起来。
可变生产工序成本
来自原始数据-生产变动成本。不同工作中心生产同一产品的生产成本可能不同。
单位工序生产小时数
就是原始数据中的工艺系数。完成该工序所需的生产流程的小时数。
生产批量大小
来自原始数据-生产批量。
- 生产流程匹配
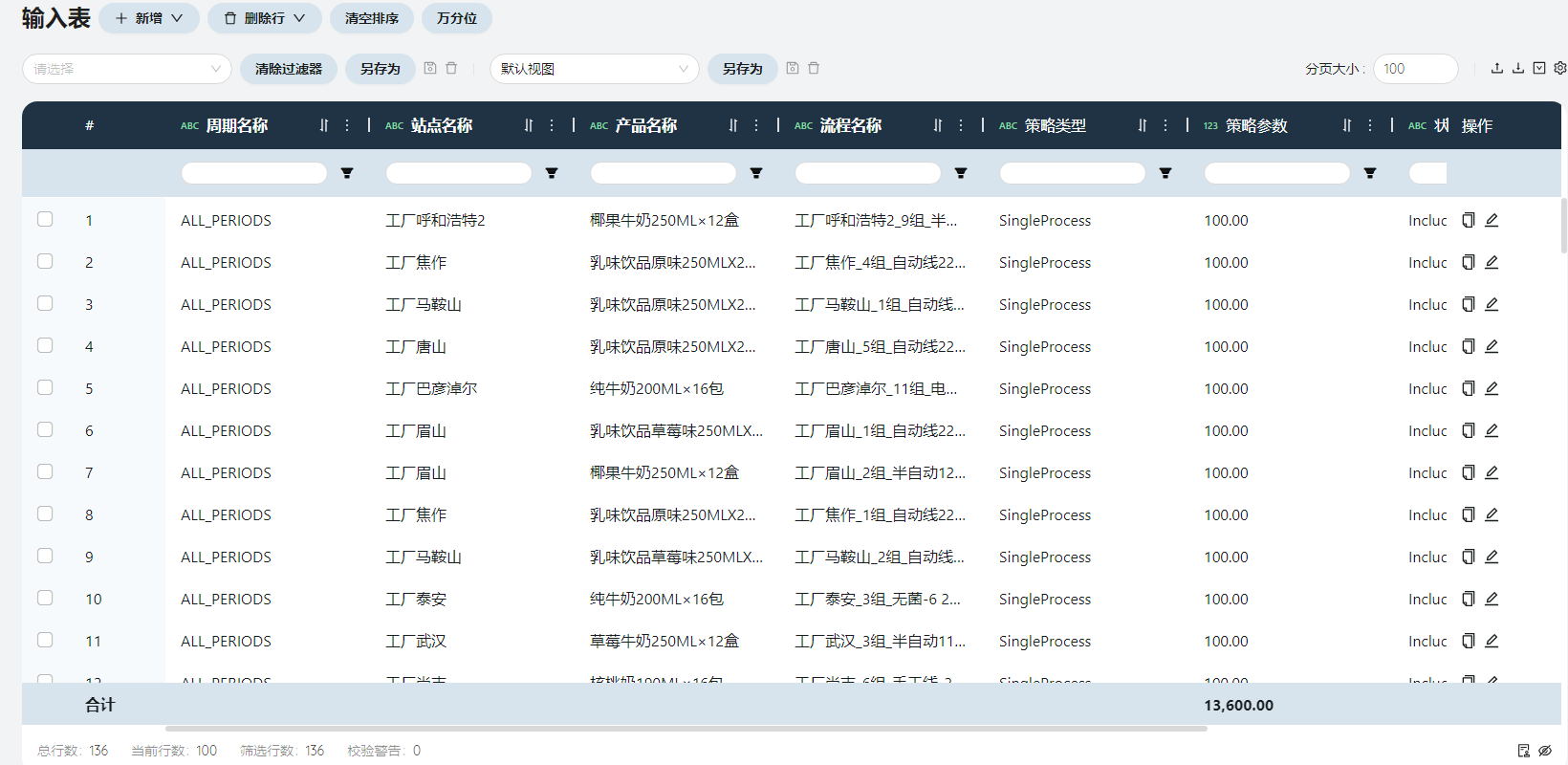
将流程名称与周期、站点(生产地)、产品名称关联起来。填写方法与物料清单匹配类似。
- 生产限制
Baseline模型的生产限制其实是每个奶源在上中下旬中的计划原奶供应数量,共14*3(42)条。
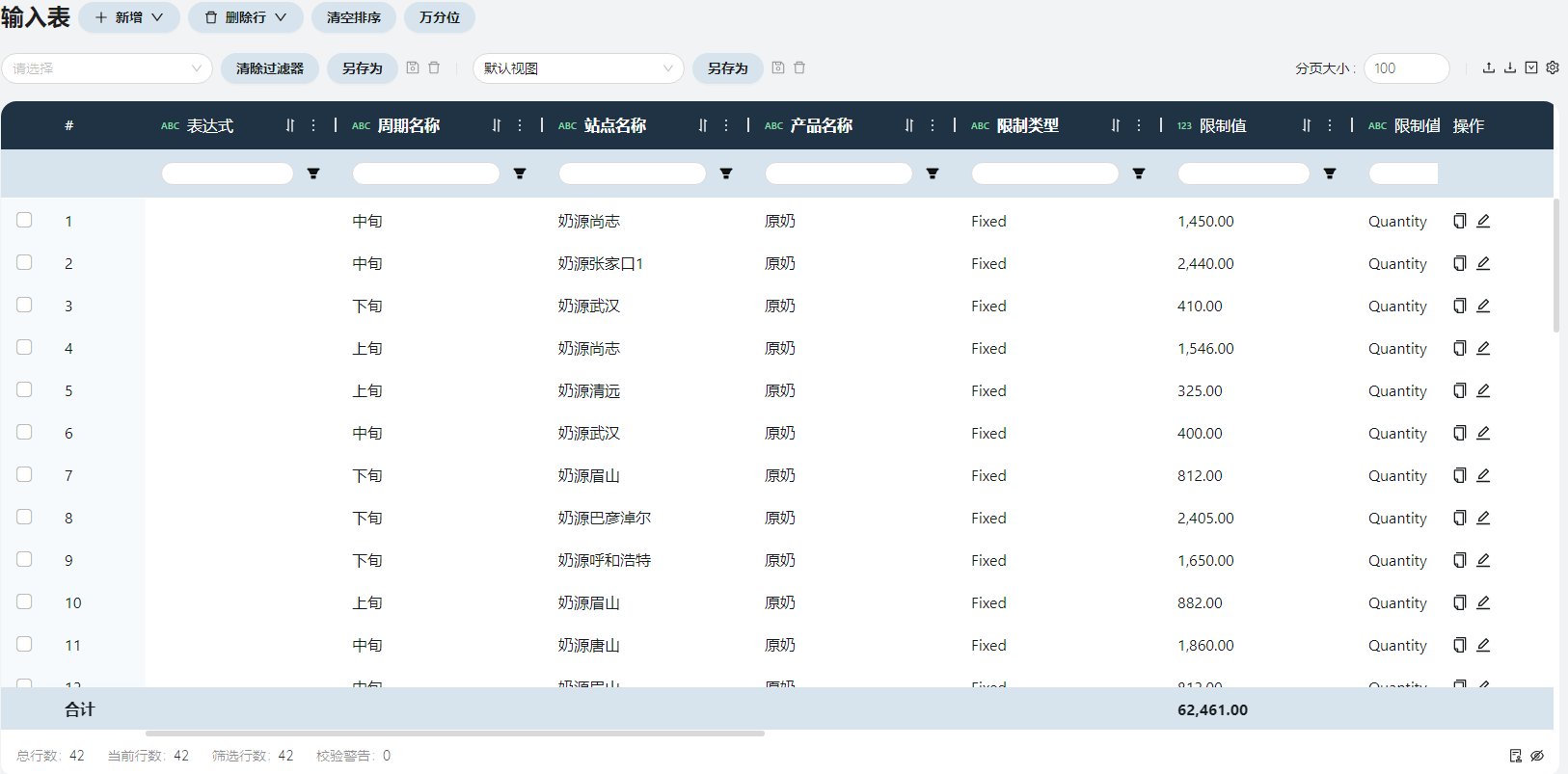
限制类型
原奶数量不可多不可少,填写Fixed。
限制值
来自原始数据-计划可用原奶。
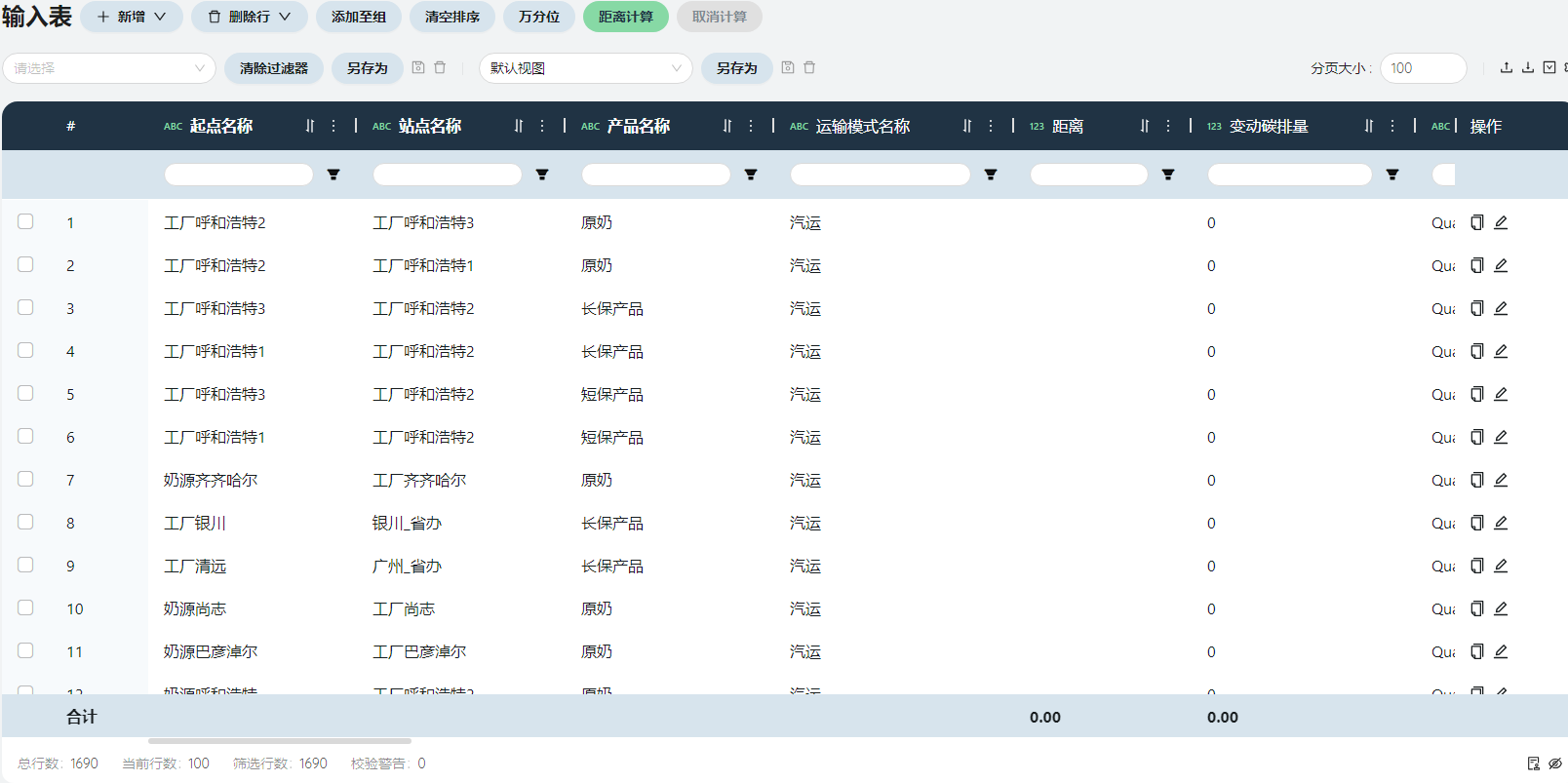
- 运输策略
包括Dummy假工厂-工厂,奶源-工厂,工厂之间的调拨,工厂-客户的各种运输模式的运输成本信息。共1690条数据。
特殊数据
从假工厂MFG_DUMMY到工厂的individual组MFG运送所有产品的线路是为了让模型自己计算期初库存数量,且不影响对模型结果的分析。运输模式随意填写,图中填写了传送。变动运输成本需要设置得比其他正常线路大很多,由此让模型在其他任何线路都不能满足需求的时候才去选择Dummy假工厂。模型会自动计算出假工厂发往各个工厂的货量,也就是期初库存。下面的字段填写说明不包含这条特殊数据。
产品名称、运输模式名称
根据原始数据-手工分销计划得到每种产品从工厂到客户的运输路线与运输模式,根据原奶调拨线路和单价得到原奶从奶源到工厂的运输路线与运输模式。原奶都是从奶源发往工厂的,对应的运输模式是汽运,共39条数据;短保产品(4种成品)从工厂发往客户,对应的运输模式也是汽运,共553条数据;长保产品(16种成品)从工厂发往客户,对应的运输模式包括汽运、海运、铁运,共1091条数据;工厂之间的调拨只发生在工厂呼和浩特1/2/3之间,使用汽运,工厂2向外运送原奶,接收1、3发来的长保产品、短保产品,共6条数据。
变动运输成本、变动成本基准
变动运输成本根据原始数据-手工分销计划以及原奶调拨线路和单价填写,在此场景中,Quantity的单位就是吨,元/吨对应的变动成本基准就是Quantity。
- 采购策略
仅需填写起点、站点、产品名称列。
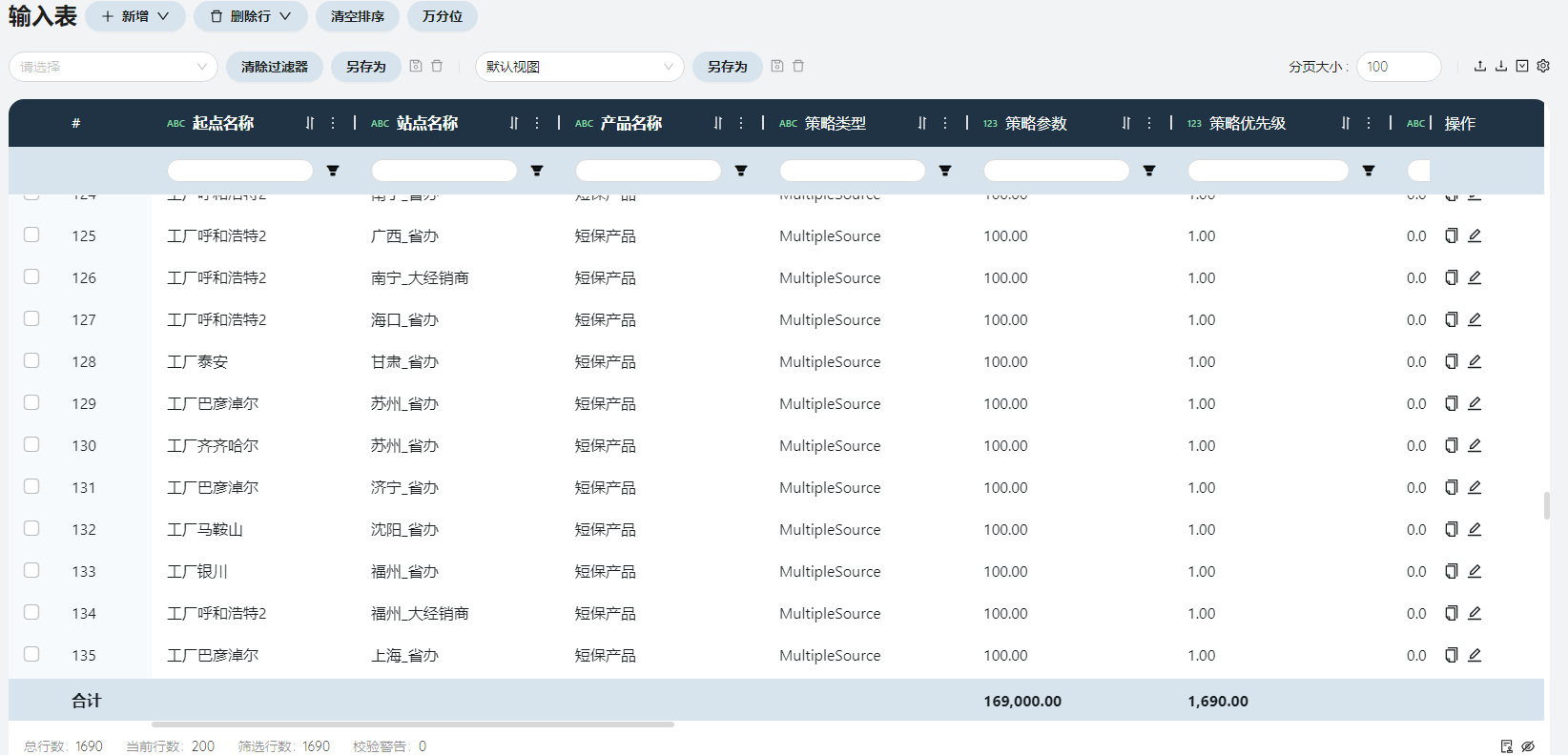
与运输策略类似,直接复制运输策略的起点、站点、产品名称列即可,共1690条。像图中一样合并工厂之间的运输线路也可以。
- 流量限制
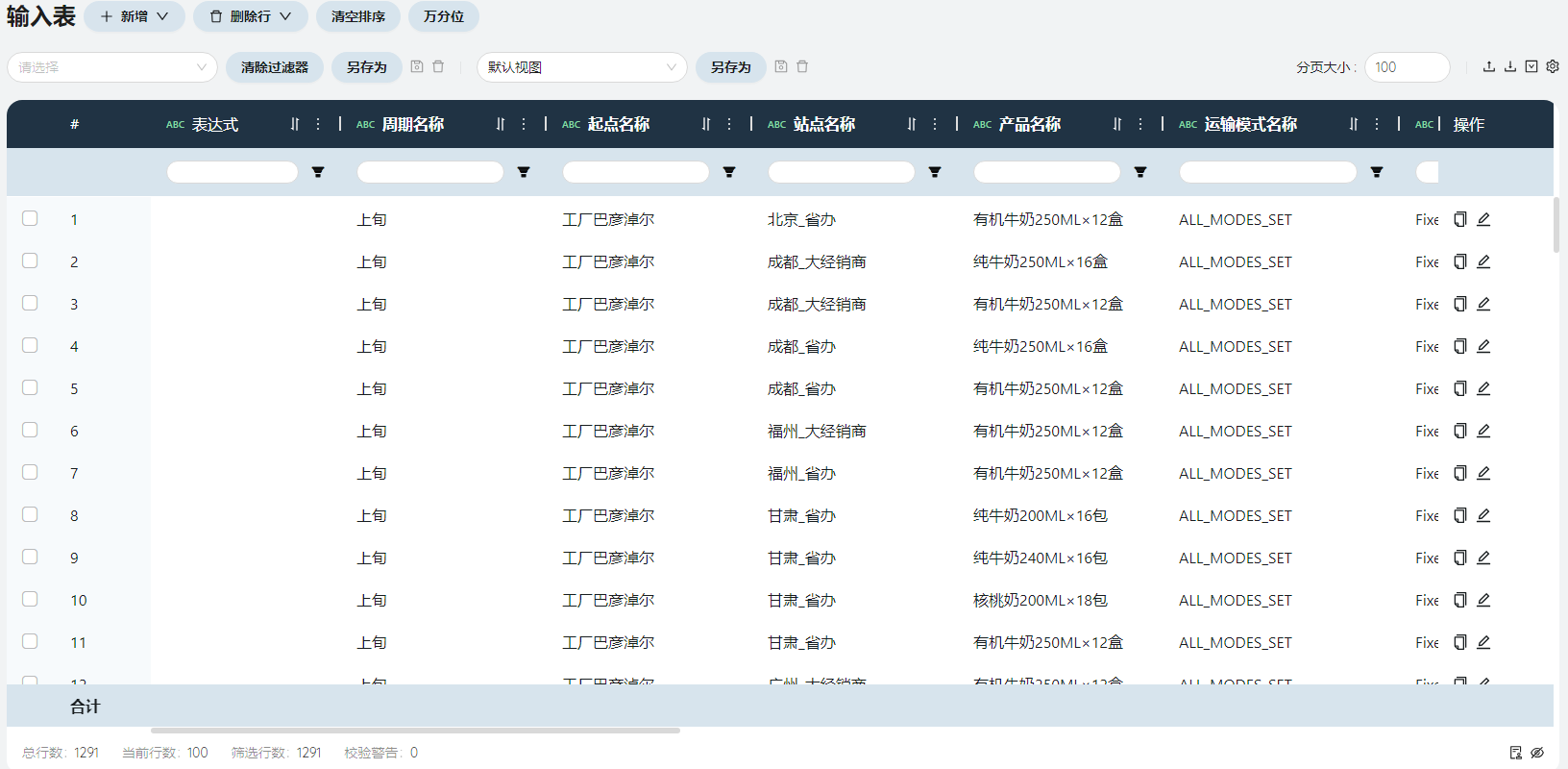
根据原始数据-手工分销计划得到每个周期每条线路运输每种产品的数量。
限制类型
填写Fixed。
- 库存策略
工厂可以储存20种成品与1种原材料(原奶)。
站点名称
填写站点的individual组:MFG。
# 模型输出
填写完输入表之后,点击左侧功能栏进入在线任务列表,点击新增任务,勾选Baseline,选择算法“网络优化(NO)”,点击添加,模型开始运行。
运行成功,点击左侧功能栏,选择对应的输出表查看。
- 网络优化汇总
展现了网络中的营收、利润、细分成本等信息。
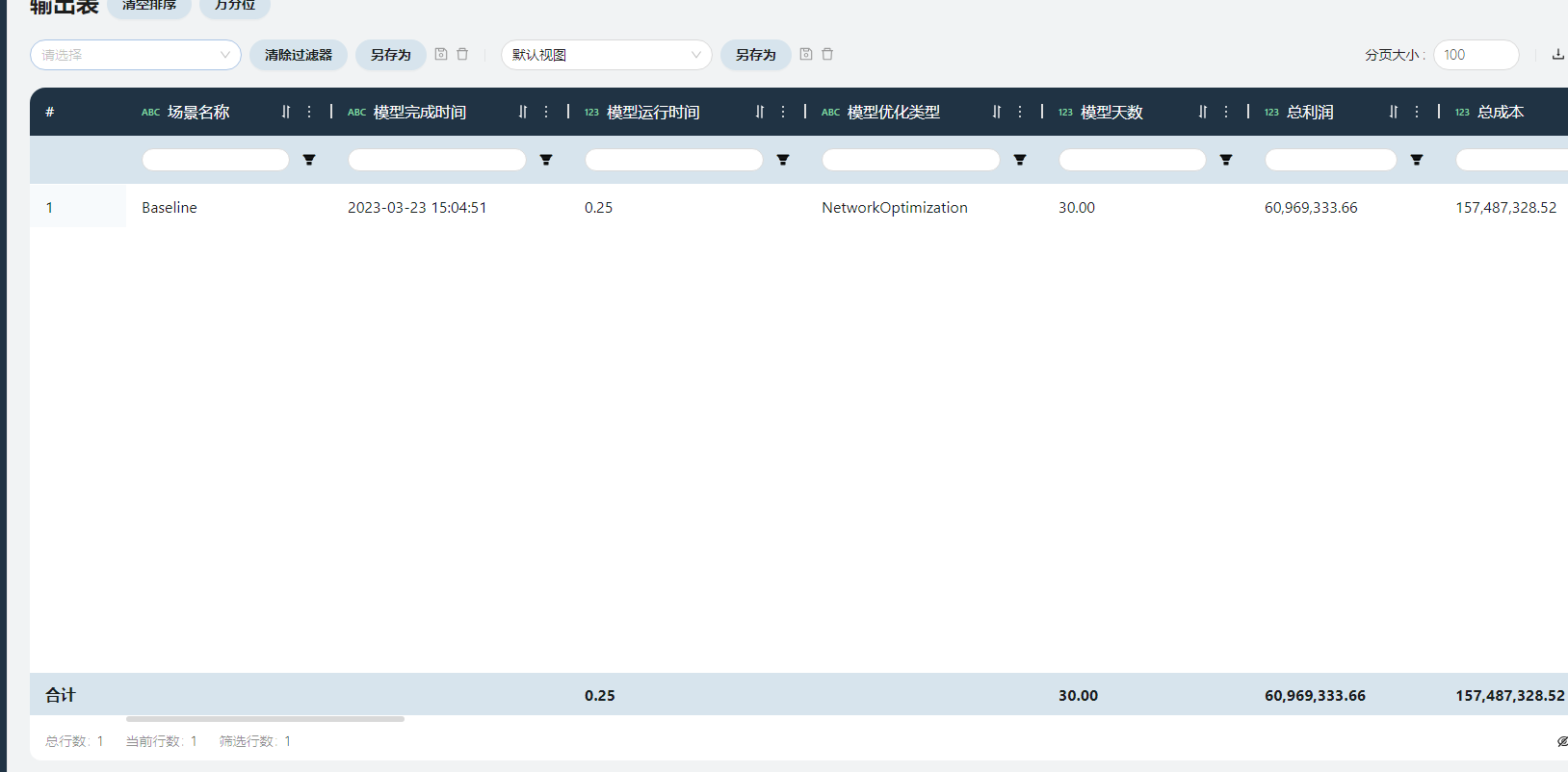
总营收
根据模型元素中产品的价格计算出。
总利润
总营收-总成本
总成本
在此场景中,等于总生产成本+总运输成本(实际上运输成本里包含了丢弃成本)。
总生产成本
在此场景中,等于每个工作中心生产每种产品的数量*单位工序成本之和。
总运输成本
在此场景中,等于运输成本+丢弃成本。
- 网络工作中心汇总
展现了每条产线在每个周期的吞吐量、生产成本、产能利用率等信息。
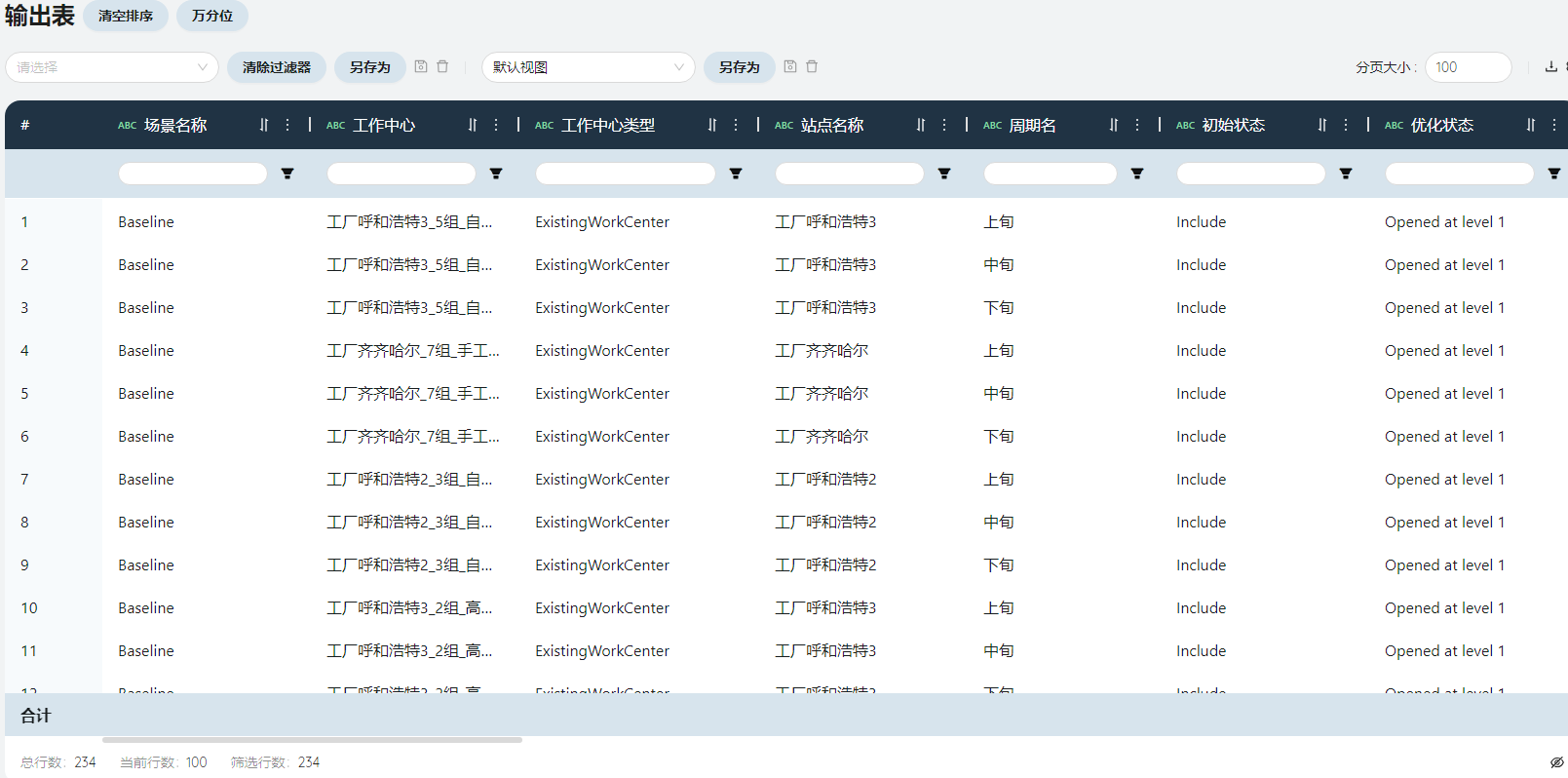
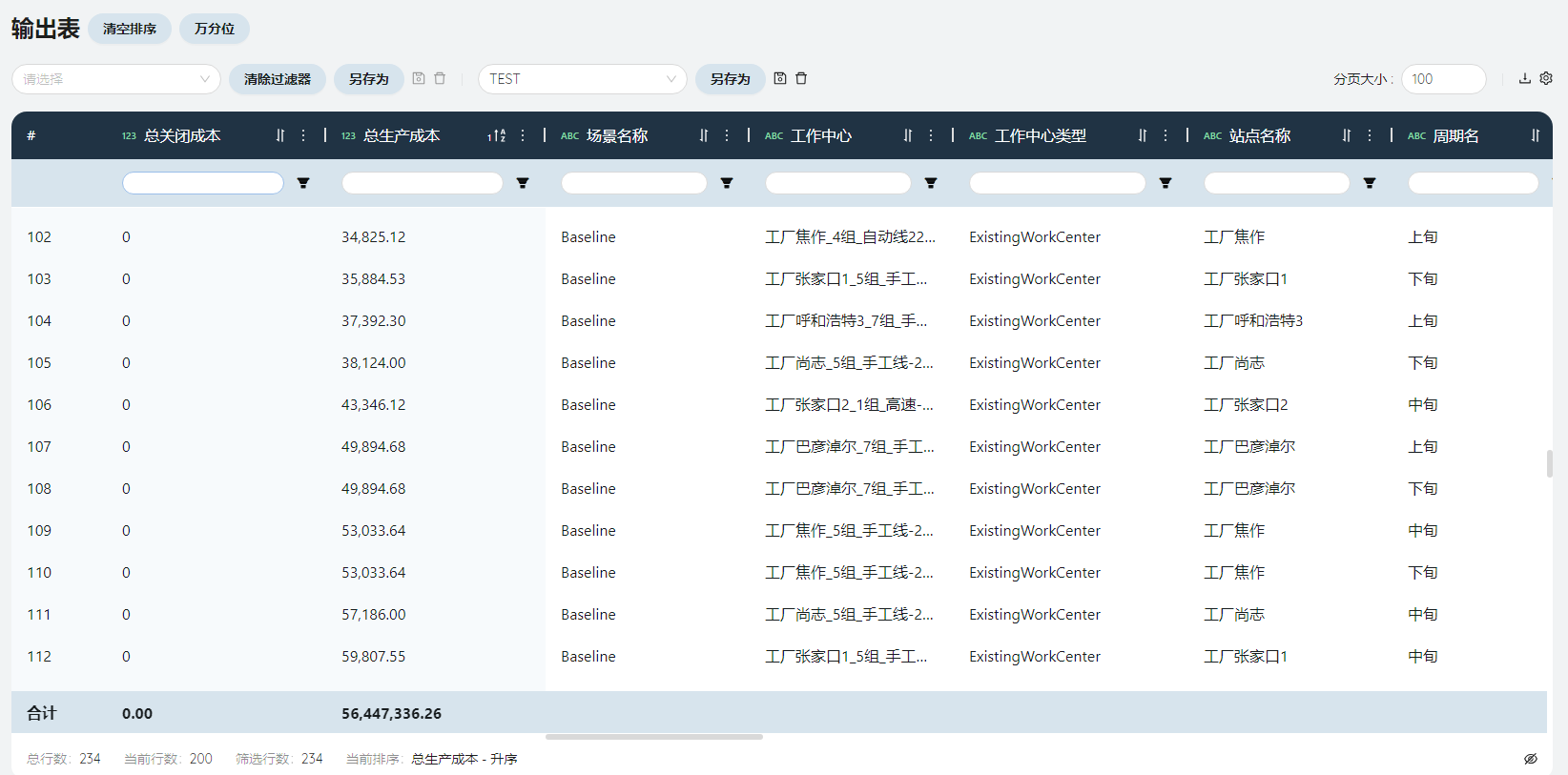
优化状态
根据工作中心的固定运营成本得到,产线的产能位于第几个阶梯。
吞吐量/吞吐量基准
根据输入表-工作中心表设置的限制值基准字段,得到吞吐量基准为Hour。
吞吐量在此场景下表示每条产线在每旬的排产时间。
总成本
在此场景下即生产成本。
吞吐数量
在此场景下,每条产线每旬实际生产的产品数量,根据吞吐量(排产时间)*单位工序生产小时数得到。
阶梯产能/阶梯产能剩余/阶梯产能利用率
在此场景下,阶梯产能即产线所在的产能阶梯的产能上限,来自输入表-工作中心多周期设置的固定运营成本字段的吞吐量上限。
阶梯产能剩余=阶梯产能-吞吐数量。
阶梯产能利用率=(阶梯产能-阶梯产能剩余)/阶梯产能。
总产能/总产能剩余/总产能利用率
在此场景下,产能只有一个阶梯,总产能=阶梯产能。
- 运输流量
在普通的运输流量表基础上,还包括每个周期每个站点丢弃产品(成品&原材料)的数量与成本信息。
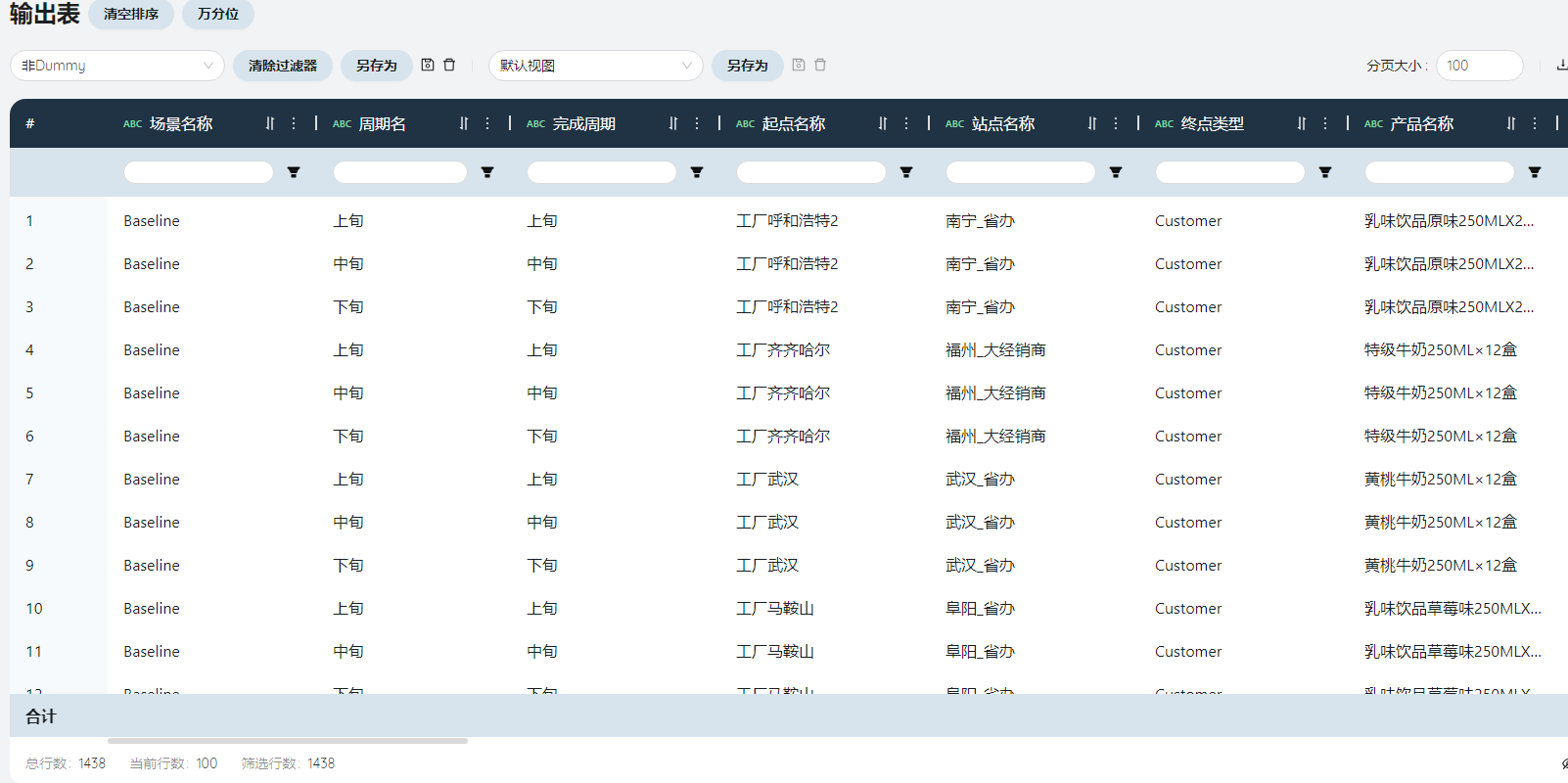
运输模式
除运输策略中涉及的运输模式外,还有DISPOSAL,表示丢弃。
- 网络生产流量
展示了每个周期每个站点生产每种产品的数量、成本细分信息。
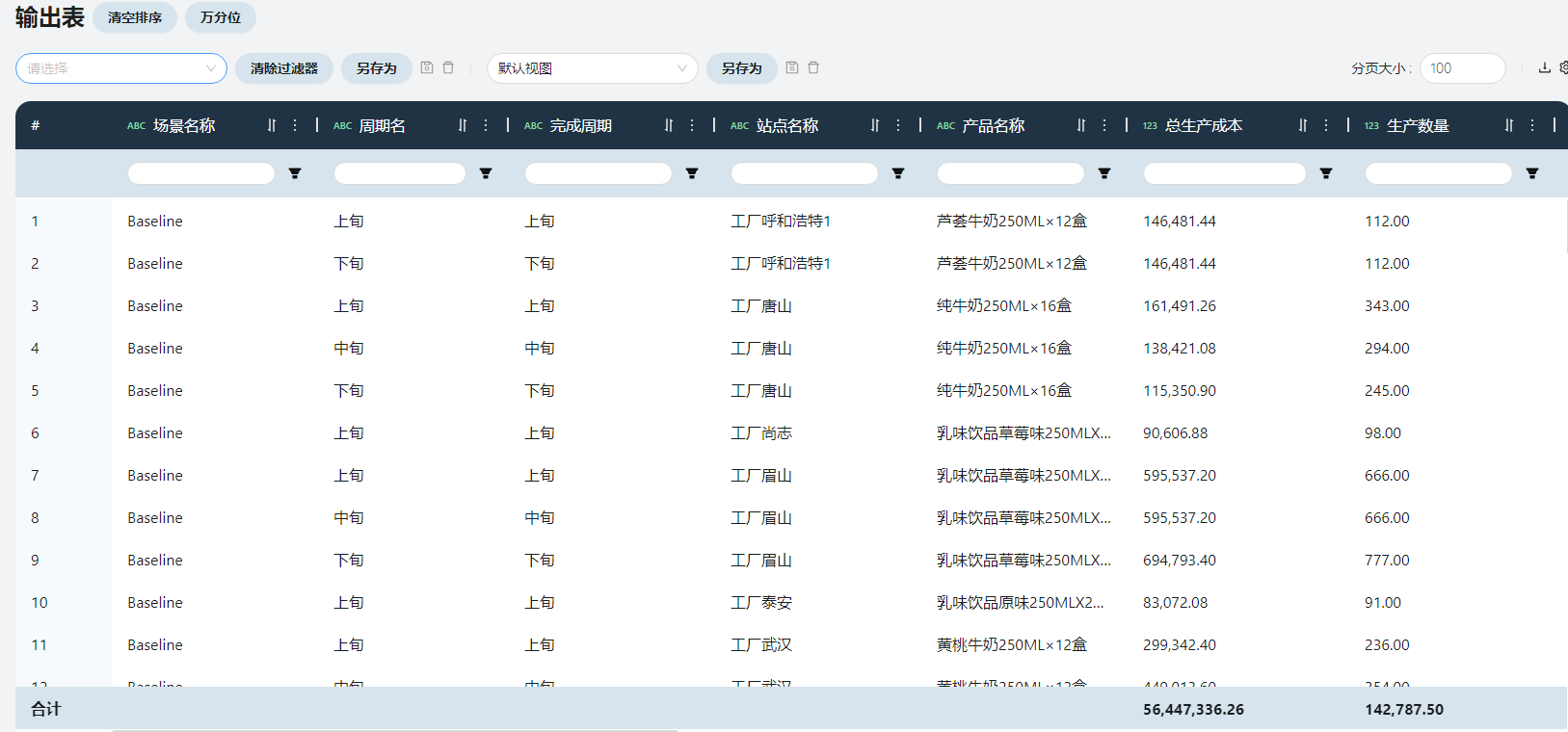
总生产成本
包括生产策略中制定的生产成本与生产流程中制定的工序成本。在此场景下,等于生产流程成本。
# 如何制定优化场景并预测优化结果?搭建Scenario.
蓝幸顾问给出了LX Milk的优化场景:
- 期初库存,原奶产量和客户订单量保持不变
- 放开成品生产和配送限制:
- 优化场景中包含输入数据中的所有可能路线和生产工厂,不再对每个工厂生产产品种类和数量进行限制,由模型根据成本进行综合考虑;
- 优化场景中每条产线的产能限制不变;
- 优化场景中不再对每旬分线路的产品流量设限制,由模型根据成本进行综合考虑。
要制定优化场景,搭建Scenario,首先需要修改输入表:新增工厂生产所有产品的生产策略、从工厂到客户的有运输报价的采购/运输策略,由于库存策略已经是所有工厂可以存放所有产品故不用修改,在流量限制表按照Baseline输出的运输流量表新增每旬从Dummy工厂传送到各个工厂的流量限制,注意修改时状态设置为Exclude,否则会影响Baseline的输入;然后可以开始搭建Scenario,关闭原先的流量限制,打开新增的从Dummy工厂传送到各个工厂的流量限制,打开新增的生产/采购/运输策略;优化场景设置完毕,最后一键运行NO,预测优化结果。
# 模型输入
- 生产策略

按图提示,添加两条生产策略,使工厂能够生产所有种类的产品(成品)。
注意:状态设置为Exclude,备注填写优化场景。
- 流量限制
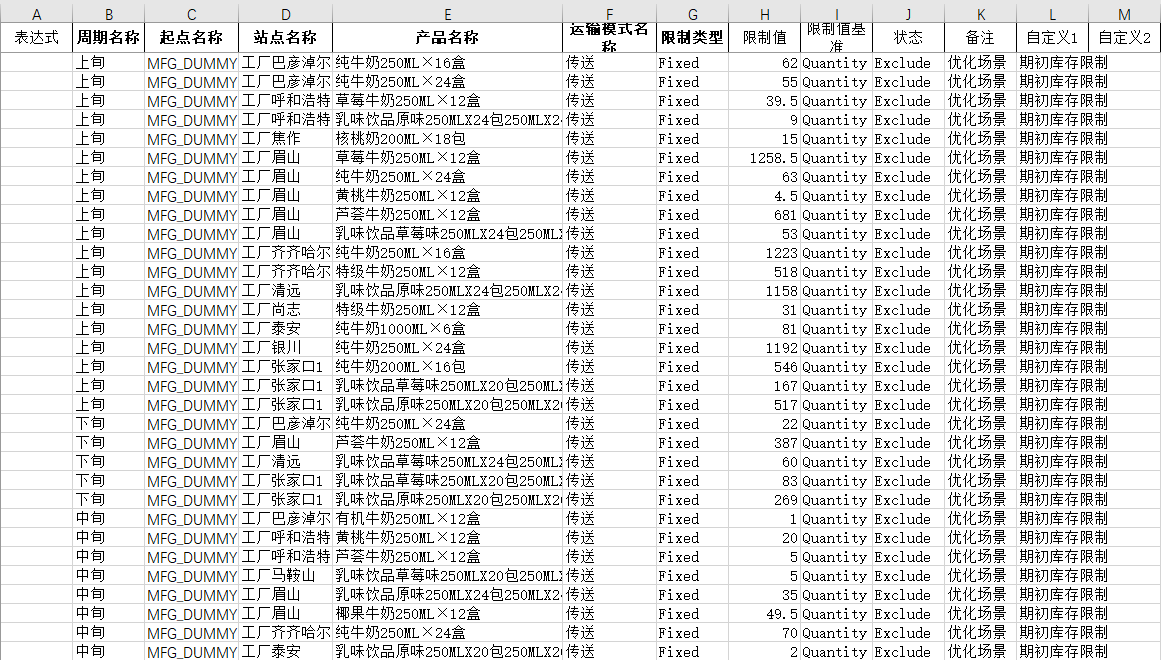
按图提示,新增流量限制,锁定每个工厂每种产品的期初库存数量。
注意:状态设置为Exclude,备注填写优化场景。
- 场景搭建

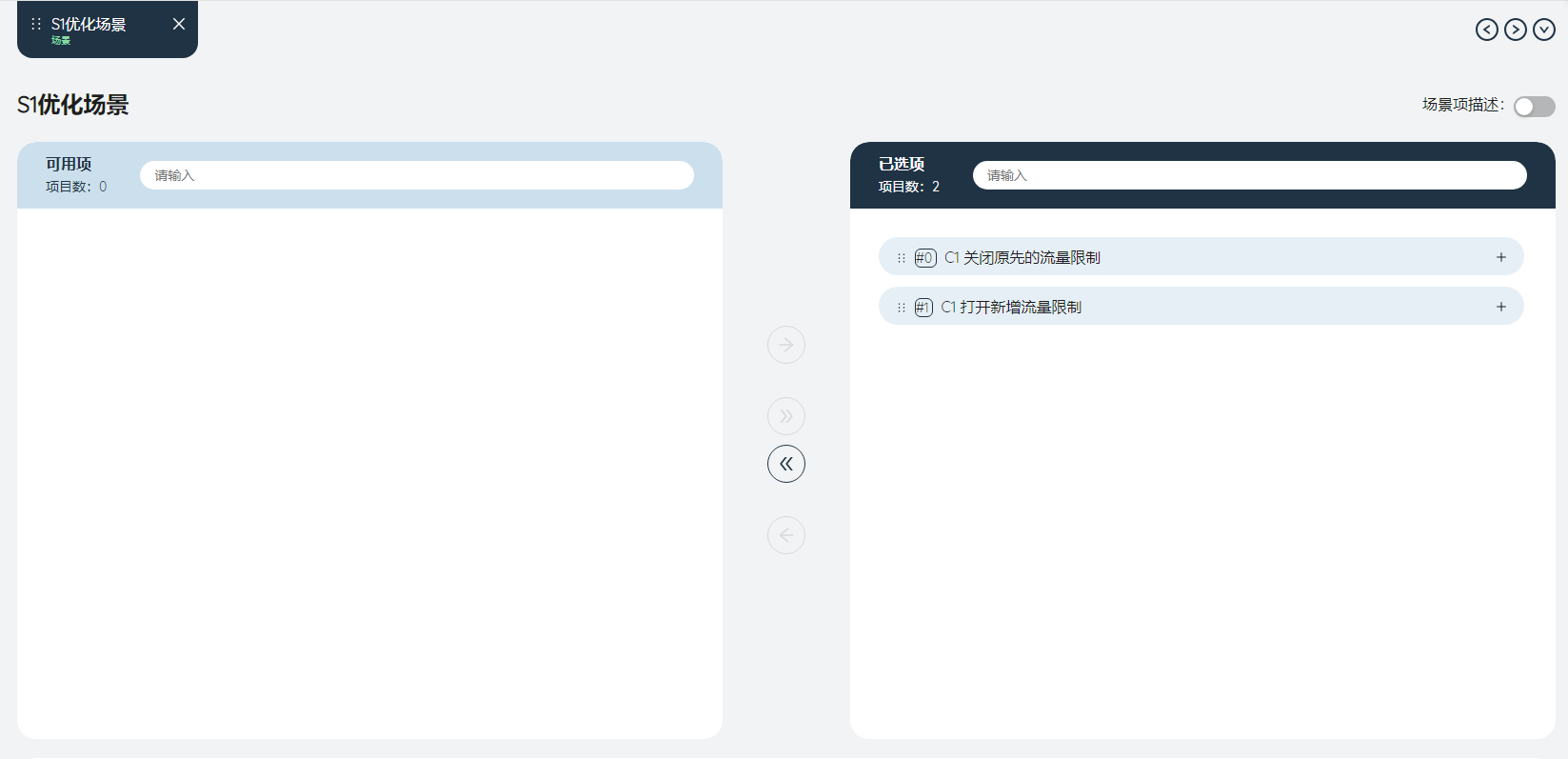
新建场景:S1 优化场景

新建场景项:C1 关闭原先的流量限制
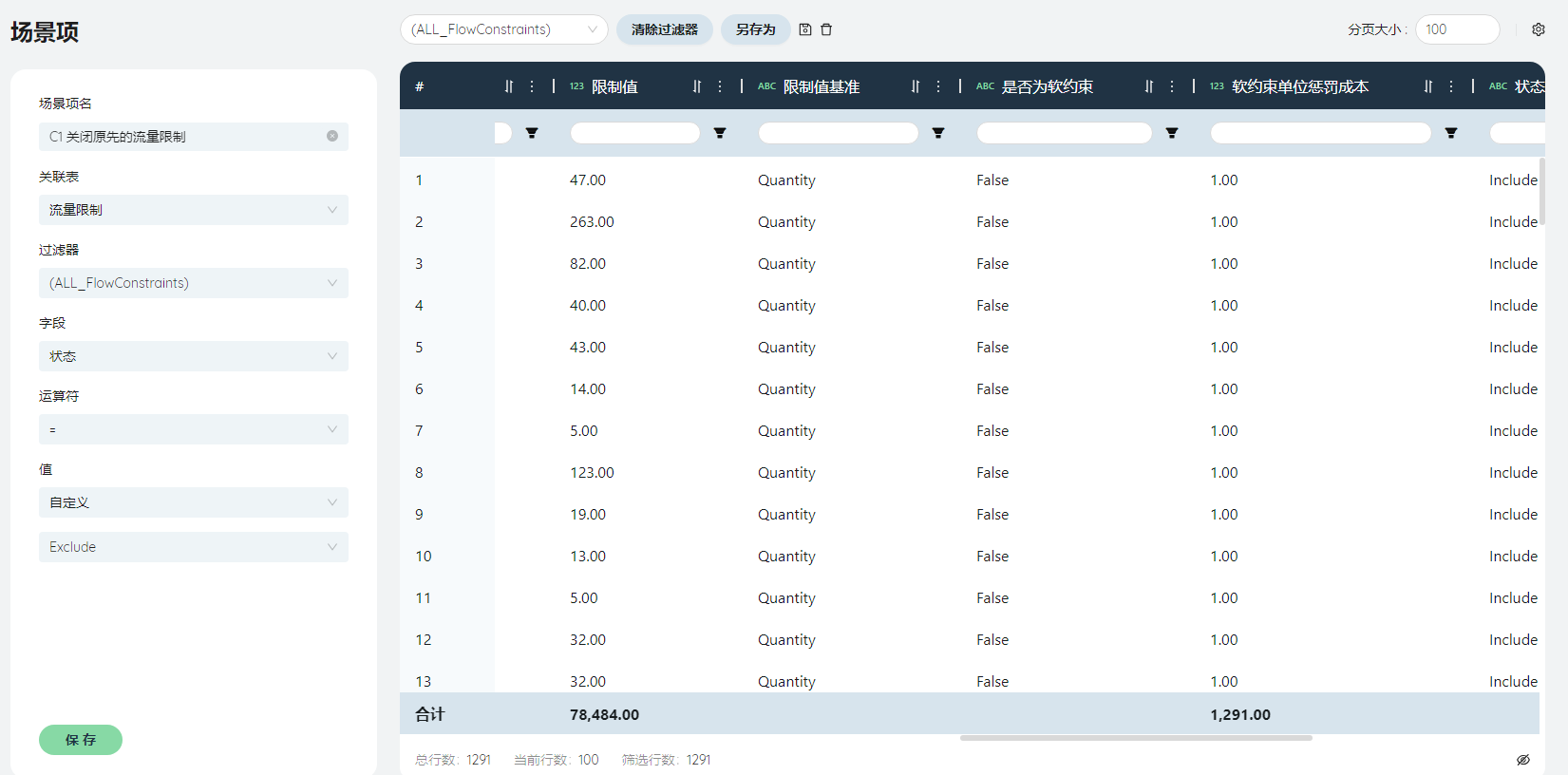
按图提示,筛选状态为include,另存筛选器,命名为Baseline,修改状态字段=Exclude。
点击保存。
新建场景项:C1 打开新增流量限制
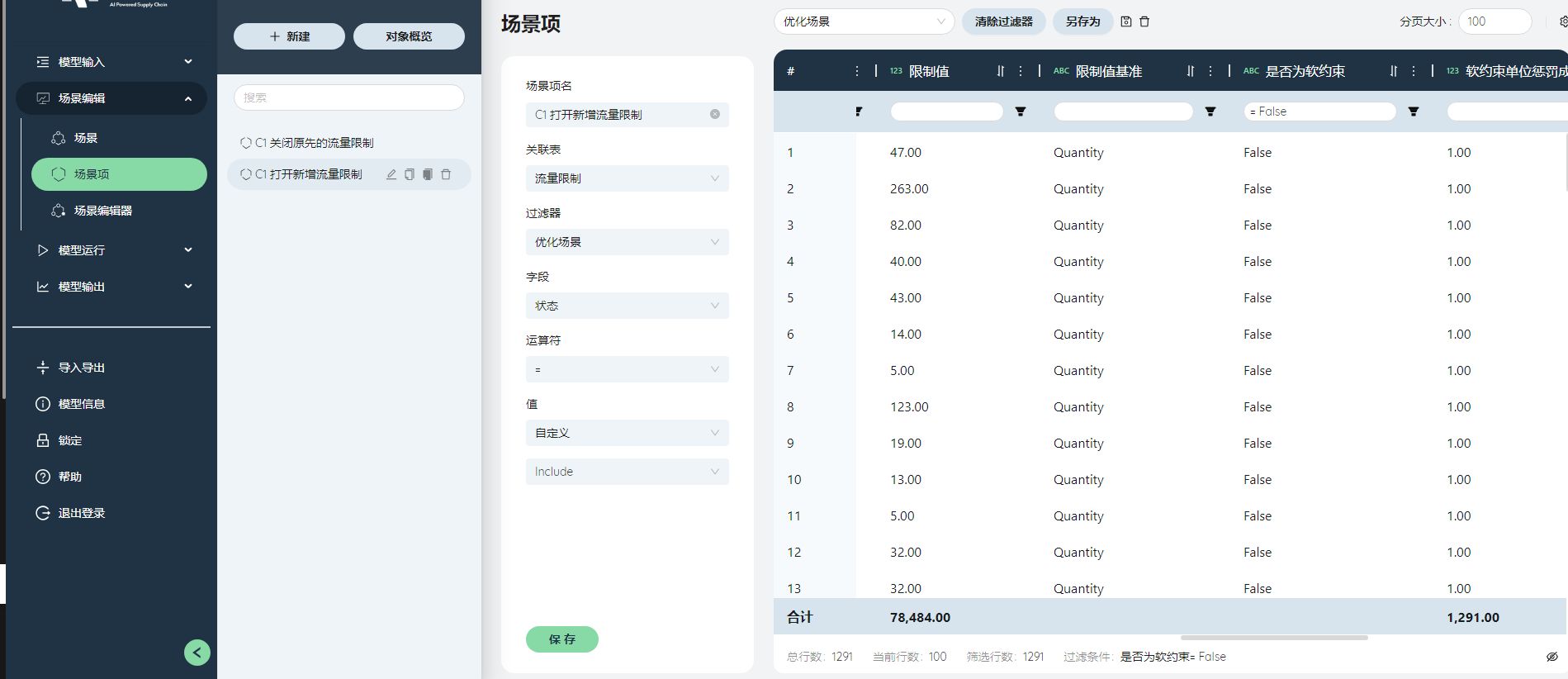
与上一个场景项类似,筛选出备注为优化场景的数据,将状态修改为include。
点击保存。
将2个场景项都加入场景中。
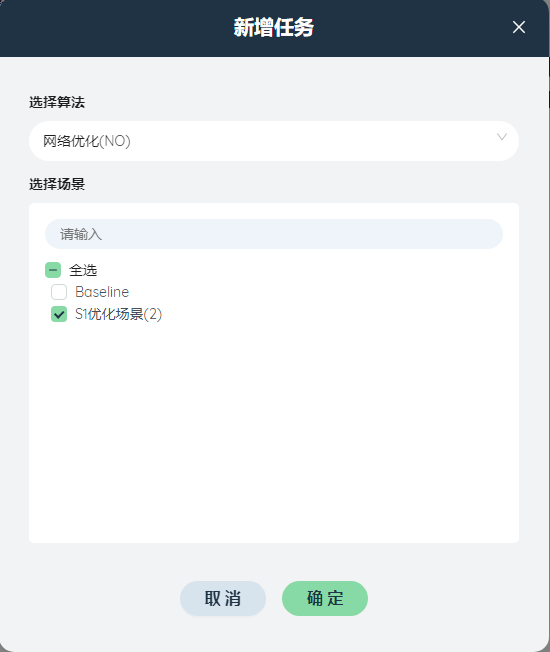
# 模型输出
在在线任务列表菜单,点击新增任务创建在线任务。算法选择网络优化(NO)算法,场景选择S1 优化场景(2),点击添加。
- 网络优化汇总

- 网络工作中心汇总
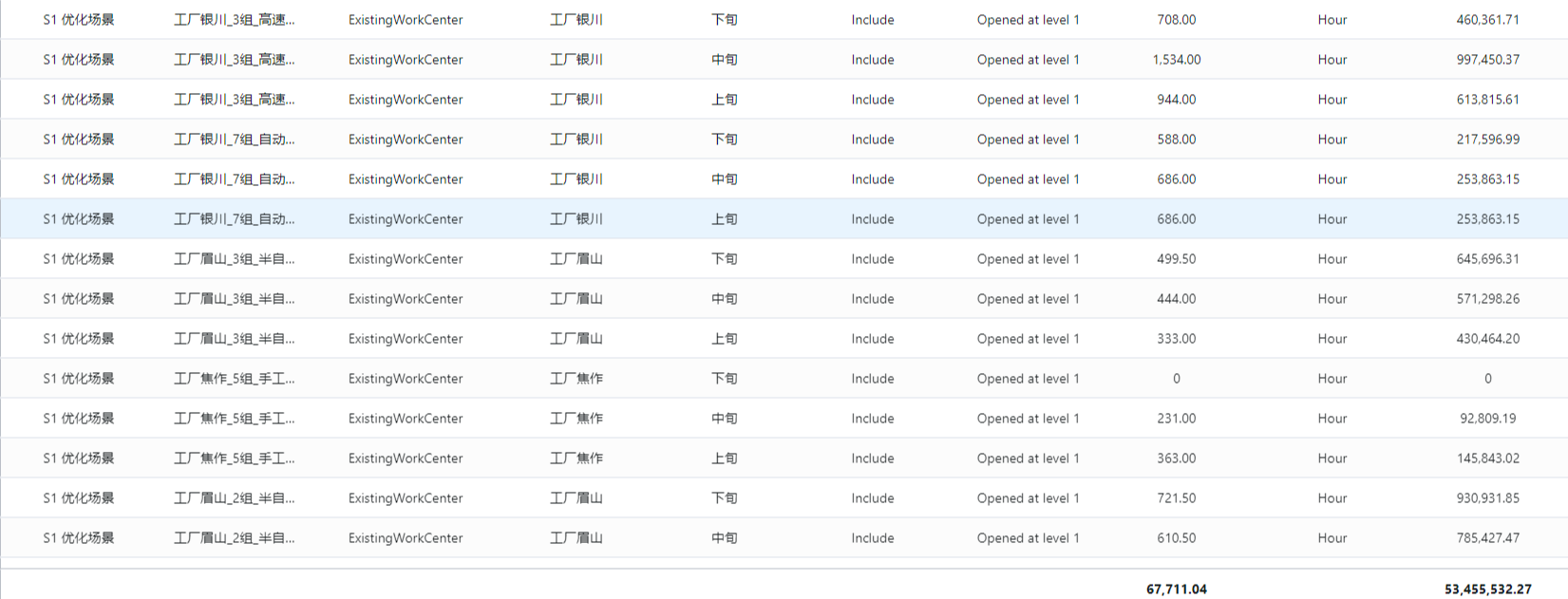
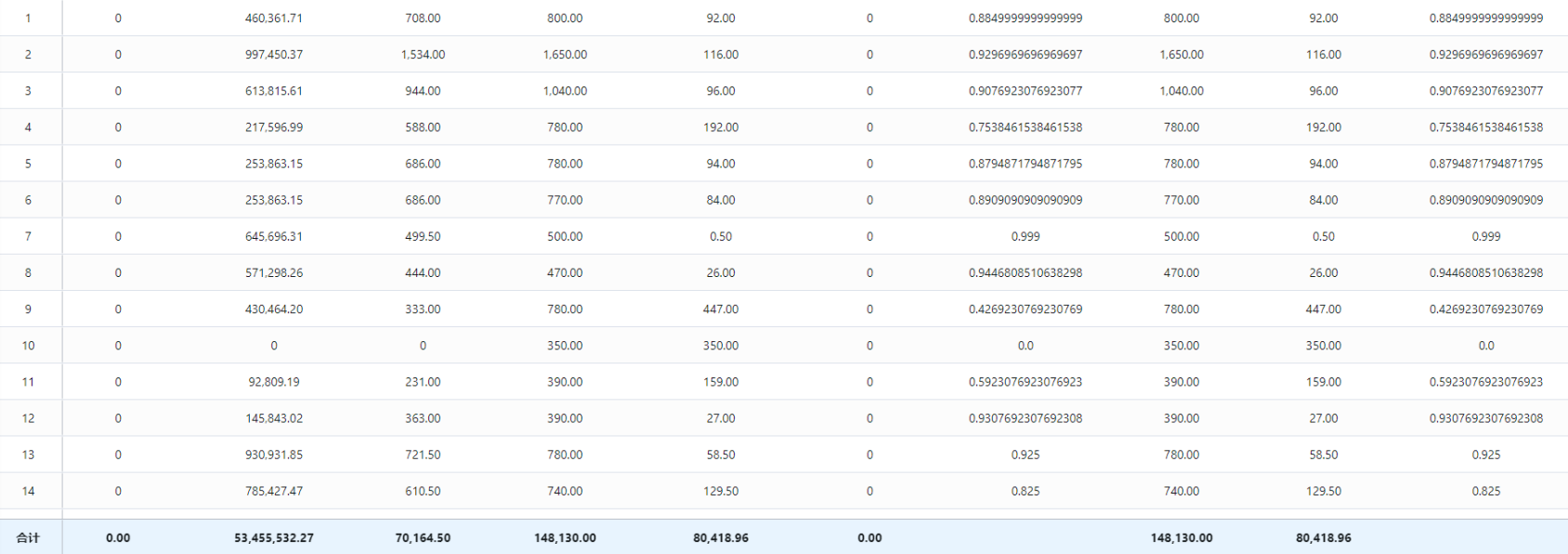
- 运输流量
- 网络生产流量
# 方案分析及对比
对从Scatlas中导出的网络优化汇总、网络工作中心汇总、运输流量表、生产流量表做数据分析。
包括对优化前后的总成本、生产情况和运输情况的对比分析。
# 优化前后网络成本对比
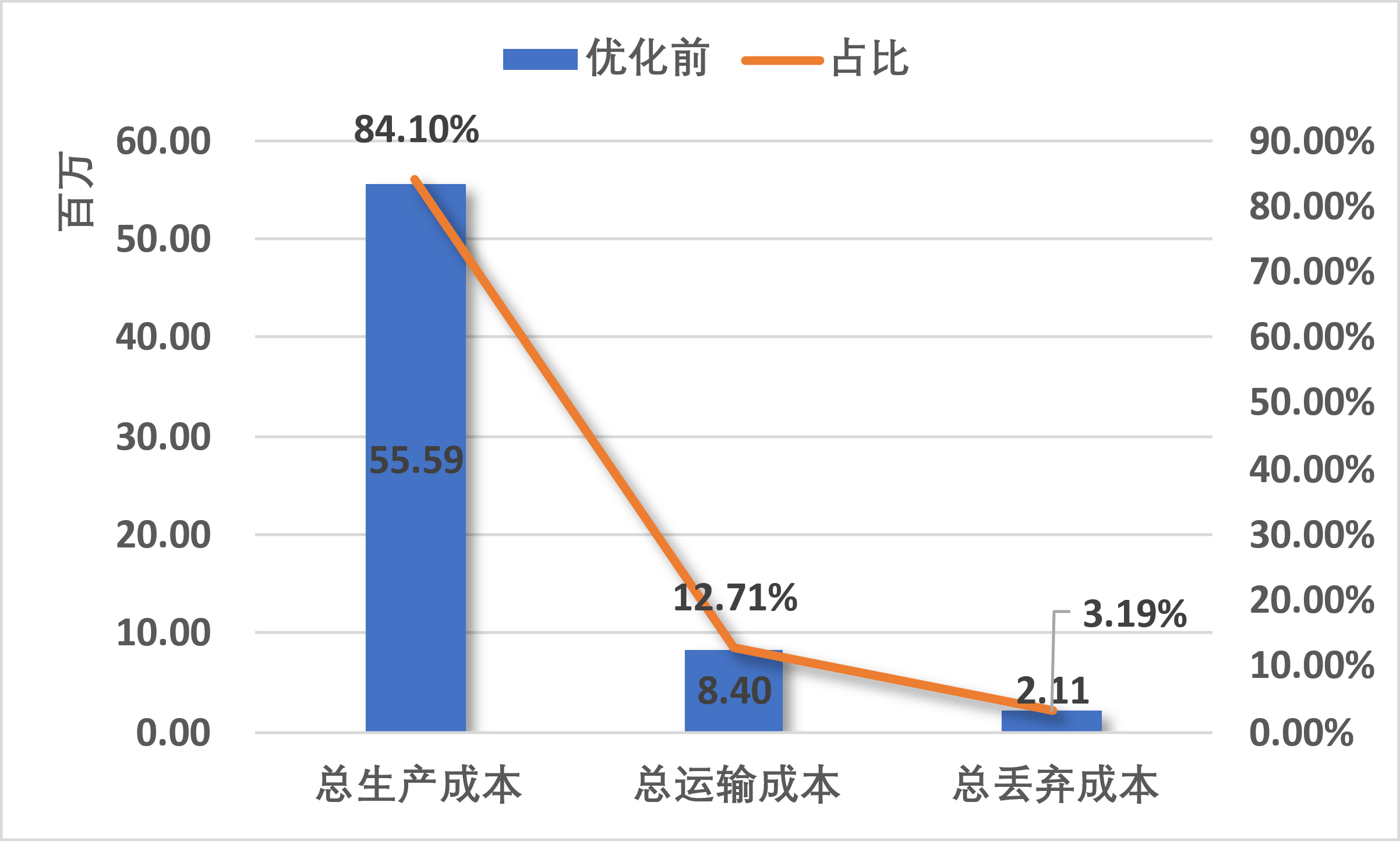
Baseline网络成本构成
# 优化后网络成本构成
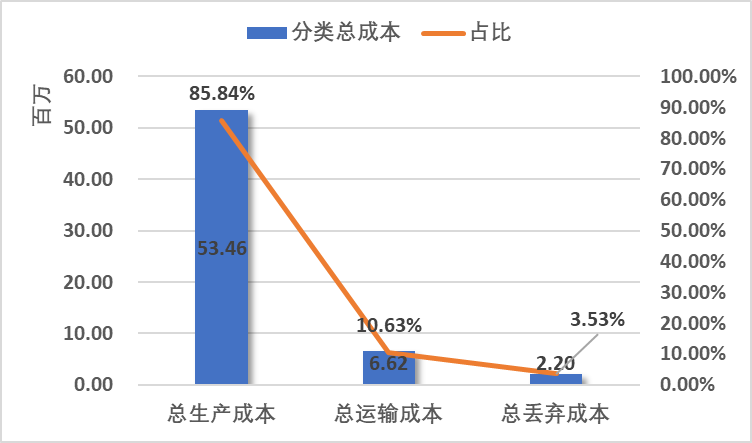
总需求量和期初库存量不变。
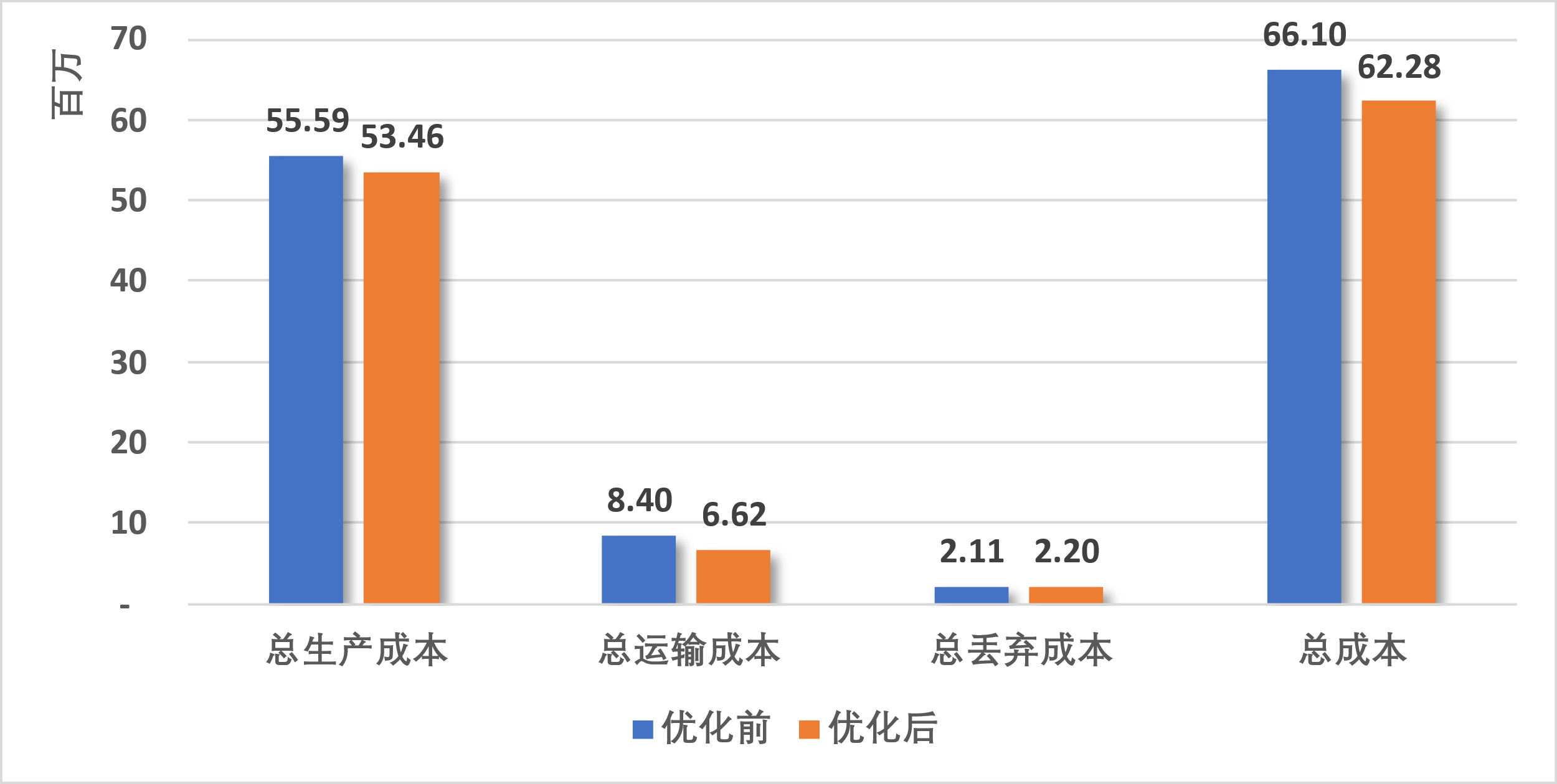
总生产成本:优化后下降了3.84%,大约2,136,146元;
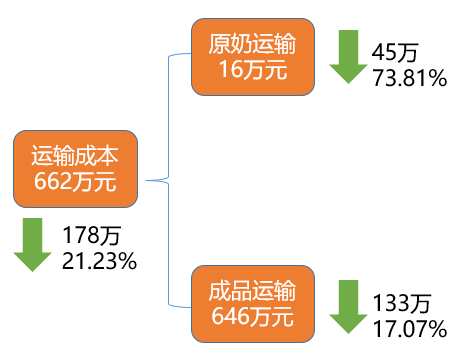
总运输成本:优化后下降了21.23%,大约1,783,566元;
总丢弃成本:优化后上升了4.51%,大约95,030元;
总 成 本:优化后下降了5.79%,大约3,824,683元。
# 优化前后生产情况对比
不同工厂生产同一种产品的单位成本和原奶消耗量不同,优化前后总生产成本和总原奶消耗量略有变化。
优化前后每种产品的平均生产成本
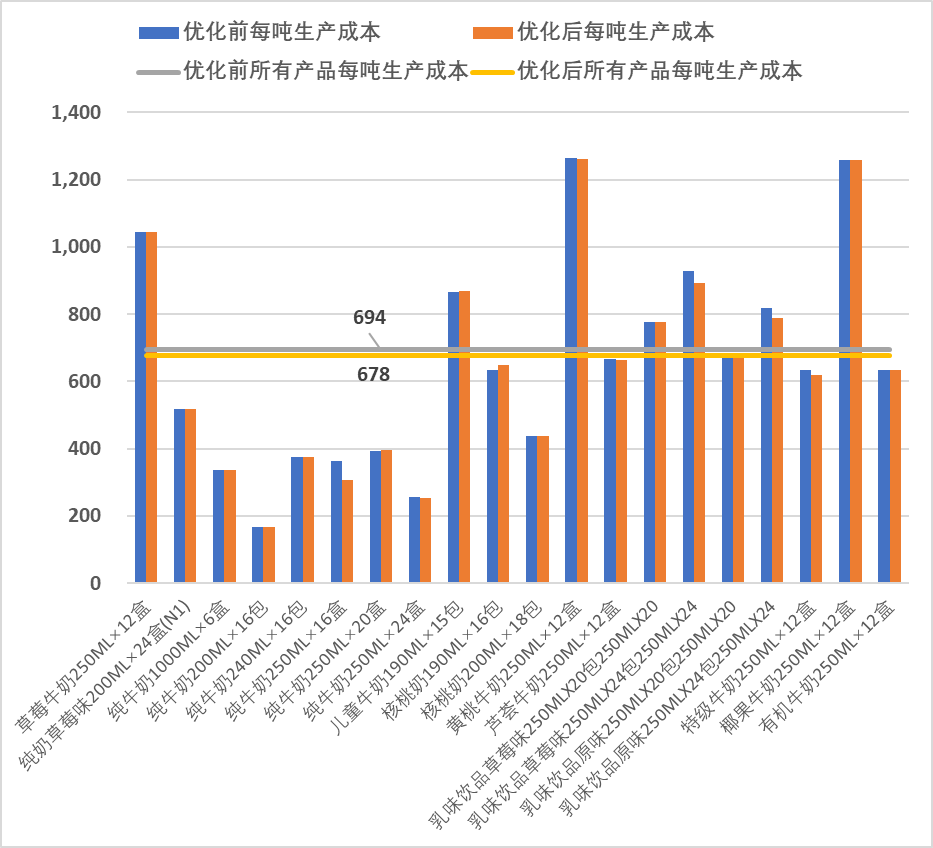
按旬汇总优化前后的生产数量与每吨成本
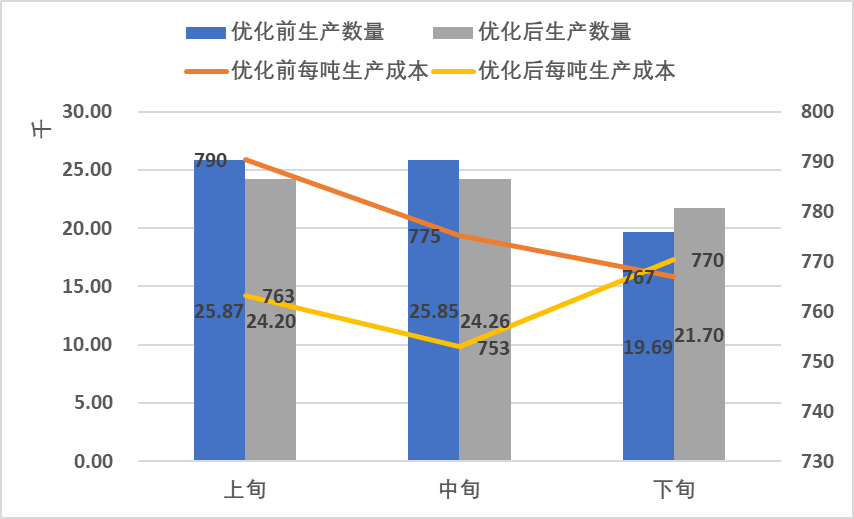
优化前后所有产品的平均每吨生产成本从¥694降低到¥678。
优化后上旬中旬的生产数量与单位成本下降,下旬的生产数量与单位成本上升。
优化后总生产成本降低3.84%。
优化前后按产能利用率汇总的各旬开工产线数目
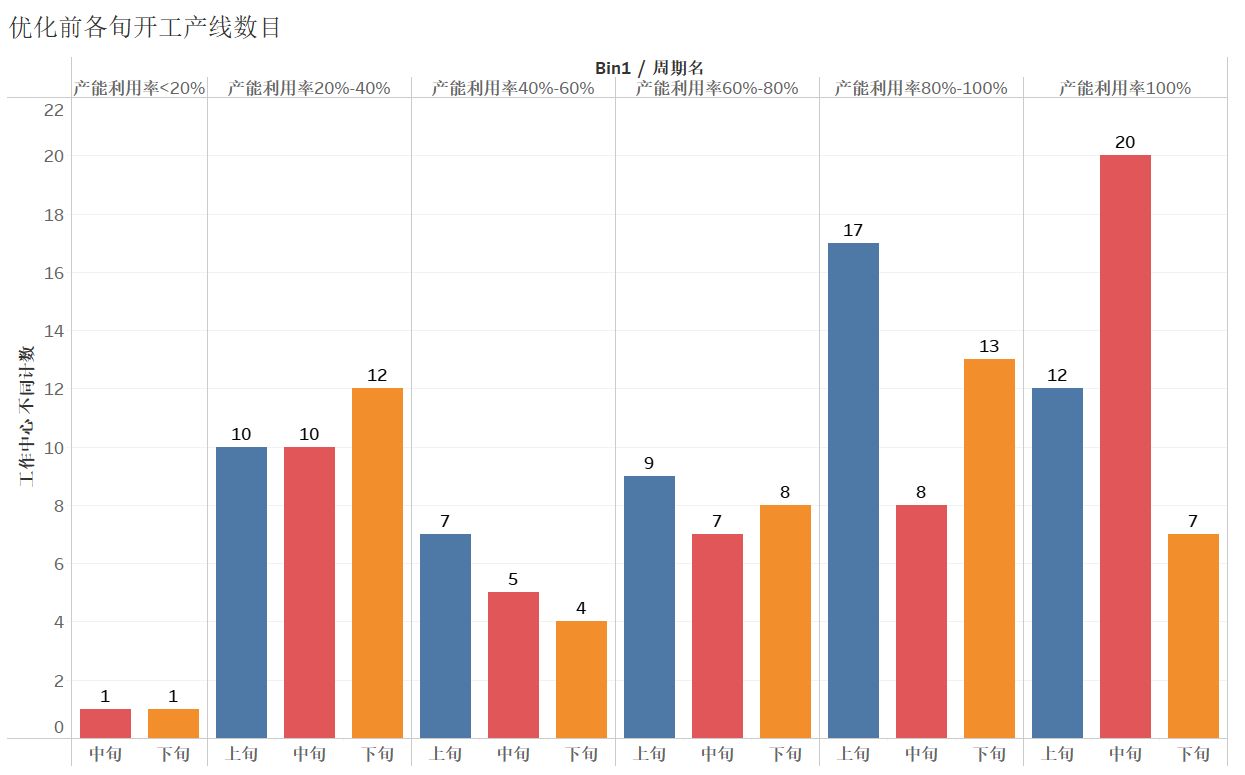
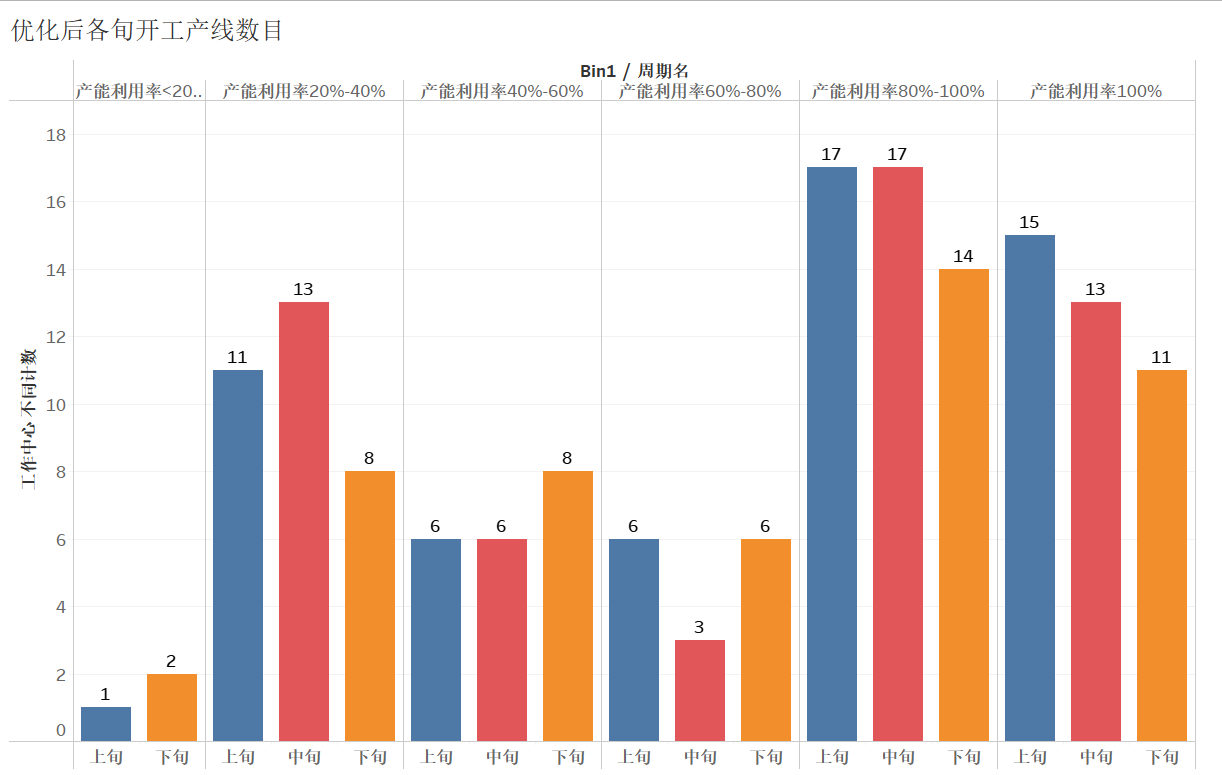
优化前开工(利用率>0)的产线,上旬有56条,中旬有52条,下旬有49条。
优化后开工(利用率>0)的产线,上旬有55条,中旬有51条,下旬有45条。
优化前后生产线平均产能利用率
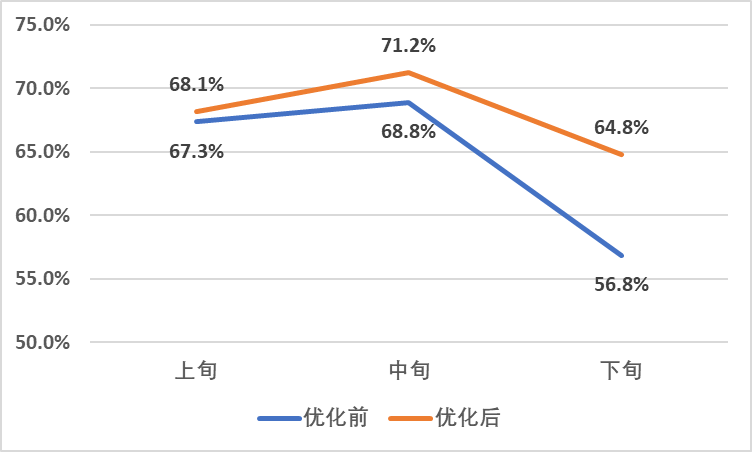
每旬利用率大于0的产线平均产能利用率均优于优化前。
优化前后运输情况对比
优化后运输成本细分
优化前后原奶调拨量及运费对比
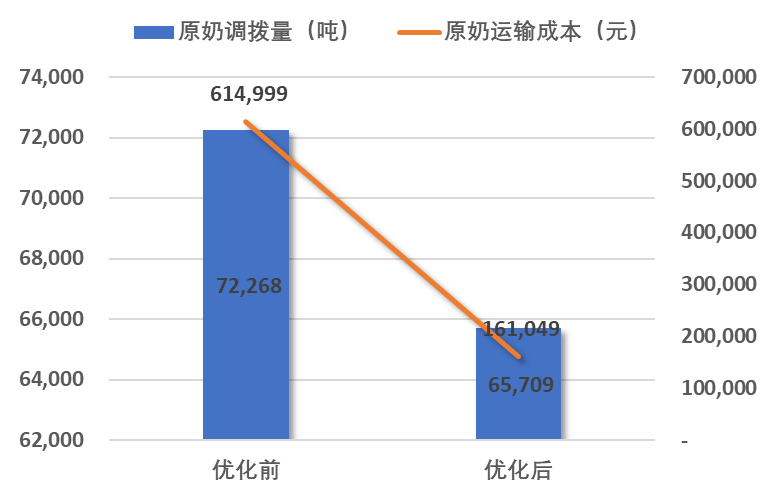
优化后原奶调拨量减少,总生产量不变,原奶消耗总量基本不变,异地原奶调拨减少。
优化前后成品配送平均距离和运费对比
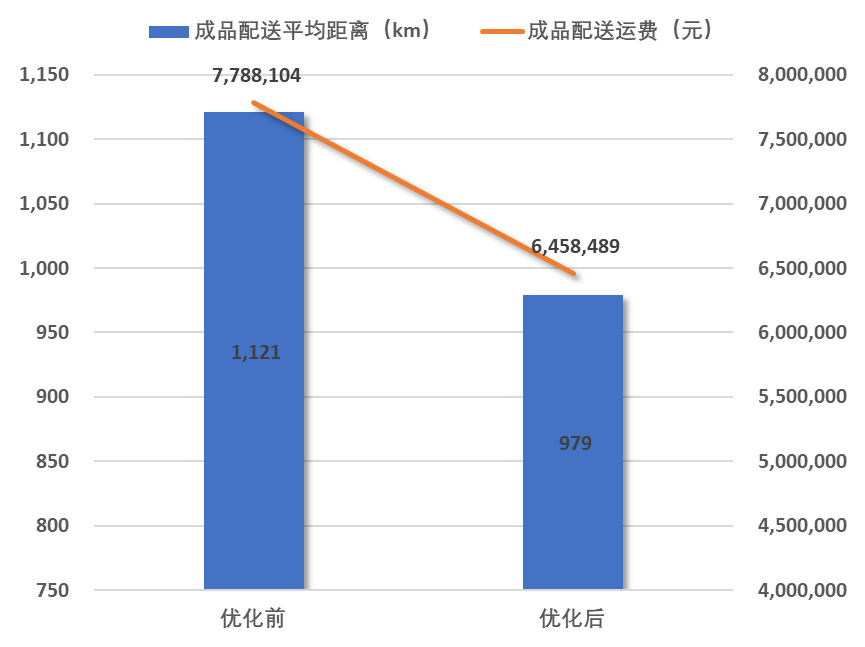
总需求量不变,总运费降低,优化后客户由距离更近的工厂配送,优化后平均配送距离降低,客户服务时效提高。
按运输模式汇总优化前后运输量对比(吨)
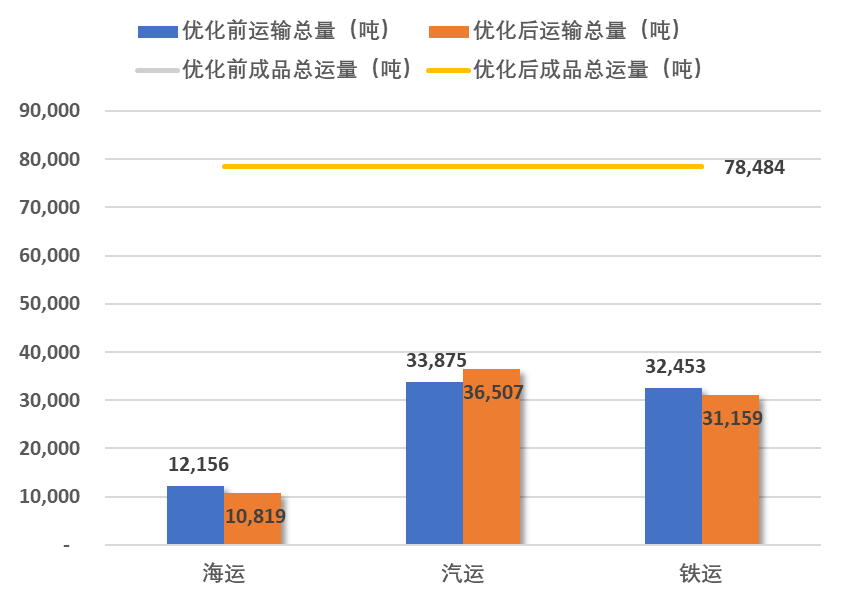
按运输模式汇总优化前后运输成本对比
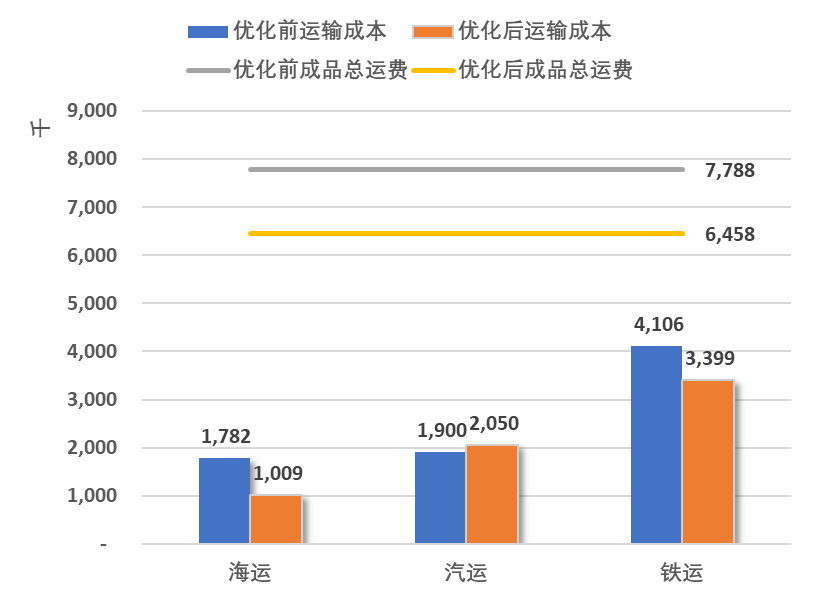
成品运输铁运和海运运输总量和成本均降低,汽运运输总量和成本增加。
优化后总运费下降,因为选择了离客户距离较近的工厂配送;优化后汽运运量增加,短距离运输海运和铁运转换为汽运。
帮助文档 →